Java递归函数Recursive算法讲解系列五
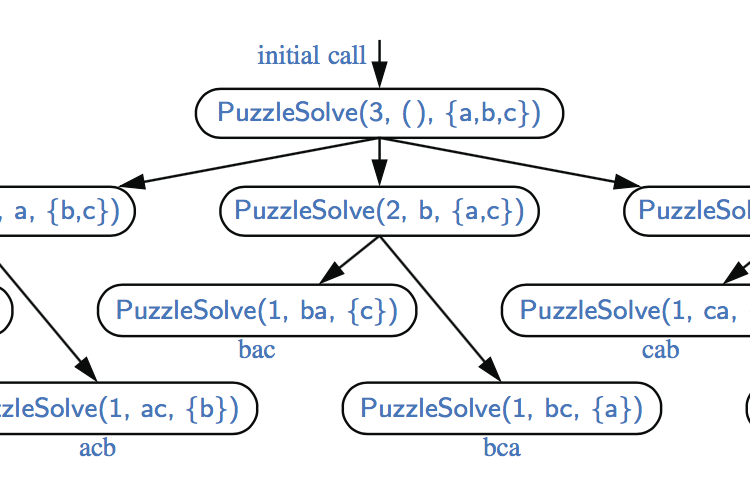
递归的缺点和问题 虽然递归是一种非常强大的工具,但它很容易被以各种方式滥用。在本节中,我们将研究几个实施不当的重新诅咒会导致严重的效率低下的情况,并讨论一些识别和避免此类陷阱的策略。 我们首先回顾上一章文章中定义的元素唯一性问题。我们可以使用下面的递归公式来确定序列的n个元素是否都是唯一的。作为基本情况,当n=1时,元素通常是唯一的。对于n≥2,当且仅当前n−1个元素是唯一的,最后n−1个元素是唯
递归的缺点和问题 虽然递归是一种非常强大的工具,但它很容易被以各种方式滥用。在本节中,我们将研究几个实施不当的重新诅咒会导致严重的效率低下的情况,并讨论一些识别和避免此类陷阱的策略。 我们首先回顾上一章文章中定义的元素唯一性问题。我们可以使用下面的递归公式来确定序列的n个元素是否都是唯一的。作为基本情况,当n=1时,元素通常是唯一的。对于n≥2,当且仅当前n−1个元素是唯一的,最后n−1个元素是唯
用递归反转序列 让我们考虑一个数组的n个元素的倒序问题,以便第一个元素成为最后一个元素,第二个元素成为倒数第二个元素,依此类推。我们可以使用线性递归来解决这个问题,通过观察序列的反转可以通过交换第一个和最后一个元素,然后递归地反转剩余的元素来实现。我们在代码中给出了该算法的一个实现,使用的约定是,我们第一次将此算法称为reverseArray(data,0,n−1)。 /∗∗ Reverses t

递归跟踪 为了产生不同形式的递归跟踪,我们在Java实现中包含了一个无关的print语句。该输出的精确格式有意地镜像了一个名为du的经典Unix/Linux实用程序(用于“disk usage 磁盘使用”)生成的输出。它报告一个目录所使用的磁盘空间量和嵌套在其中的所有内容,并可以生成一个详细的报告。 当在示例文件系统上执行时,我们对diskUsage方法的实现会产生下图给出的结果。在算法的执行过程
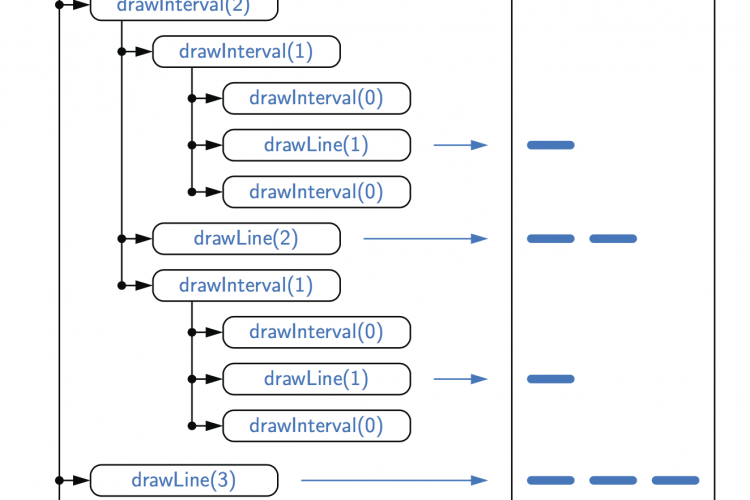
在上一篇文章中讲了递归函数的基本原理和示例,本篇继续结合具体案例讲解递归在现实中的应用。 用递归轨迹说明标尺绘图 递归drawInterval方法的执行可以使用递归跟踪可视化。然而,drawInterval的跟踪要比factorial示例复杂得多,因为每个实例都进行两次递归调用。为了说明这一点,我们将以一种类似于文档大纲的形式显示递归跟踪。见图: 调用drawInterval(3)的部分递归跟踪。
在计算机程序中描述重复的一种方法是使用循环,如Java的while循环和for循环结构。实现重复的完全不同的方法是通过一个称为递归的过程。 递归是一种方法对自身进行一次或多次调用的技术,在执行期间,或数据结构依赖于同一类型的结构。有很多例子艺术与自然中的递归。例如,分形图案是自然递归的。艺术中使用递归的物理例子是俄罗斯的Matryoshka玩偶。每个玩偶要么是实木做的,要么是空心的,里面装着另一个
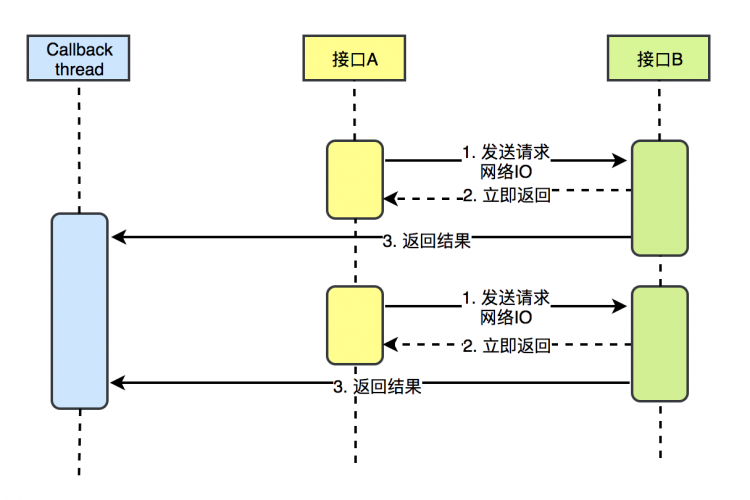
随着RxJava、Reactor等异步框架的流行,异步编程受到了越来越多的关注,尤其是在IO密集型的业务场景中,相比传统的同步开发模式,异步编程的优势越来越明显。 那到底什么是异步编程?异步化真正的好处又是什么?如何选择适合自己团队的异步技术?在实施异步框架落地的过程中有哪些需要注意的地方? 本文从以下几个方面结合真实项目异步改造经验对异步编程进行分析,希望能给大家一些客观认识: 使用RxJava

递归算法示例 布朗桥 public class Brownian { // midpoint displacement method public static void curve(double x0, double y0, double x1, double y1, double var, double s) { // stop if interval is sufficiently smal
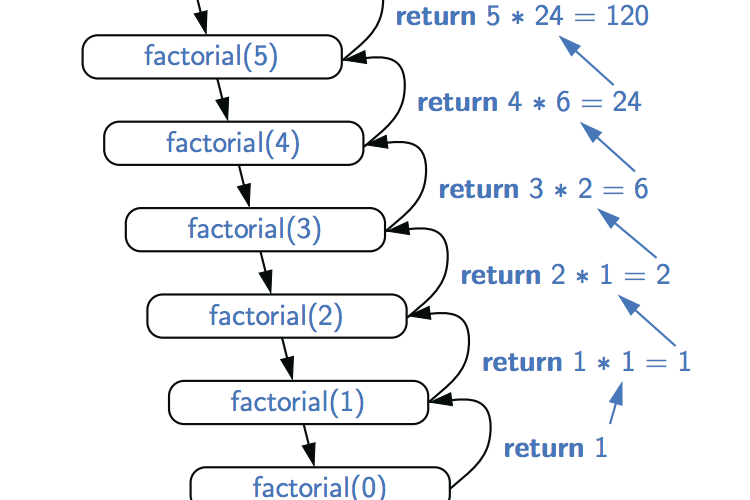
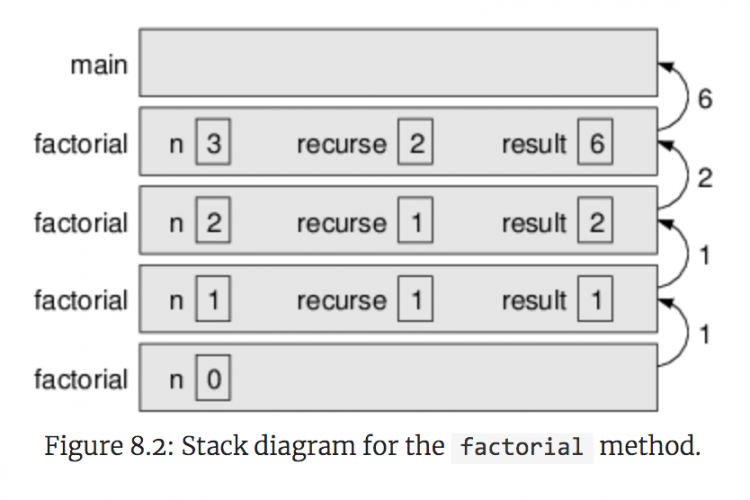
从另一个函数调用一个函数的想法立即暗示了函数调用自身的可能性。Java中的函数调用机制支持这种可能性,即递归。 下面这个视频通过代码讲述了递归的基本原理: 递归算法示例 递归的“Hello,World”是阶乘函数,它是由等式为正整数n定义的 public class Factorial { // return n! // precondition: n >= 0 and n <= 20

递归在某些算法中更难理解。一个可以自然地迭代表达的算法,如果递归地表达,可能就不那么容易理解了。 没有可移植的方法来判断深度递归可以在多大程度上不引起麻烦(机器有多少“堆栈空间”),也没有办法从太深的递归中恢复(“堆栈溢出”)。 你不能递归地做一些好事。例如,如果我要遍历一个二叉树,我可能想用For循环来完成: tree t; item *i; for (i = first (t); i != N

递归数据结构(结构递归) 递归在计算机科学中的一个重要应用是定义列表和树等动态数据结构。递归数据结构可以根据运行时需求动态地增长到理论上无限大的大小;相反,静态数组的大小必须在编译时设置。 当以递归的方式定义基础问题或待处理的数据时,递归算法特别适用。 本节中的示例说明了所谓的“结构递归”。这个术语指的是递归过程作用于递归定义的数据。 只要程序员从数据定义中派生模板,函数就采用结构递归。也就是说,
在计算机科学中,递归是一种解决问题的方法,其中解决方案依赖于同一问题的较小实例的解决方案。这类问题通常可以通过迭代来解决,但这需要在编程时识别和索引较小的实例。递归通过使用在自己的代码中调用自己的函数来解决这种递归问题。 这种方法可以应用于许多类型的问题,递归是计算机科学的核心思想之一 递归的力量显然在于可以用一个有限语句定义一个无限的对象集。同样地,一个有限的递归程序可以描述无限多的计算,即使这
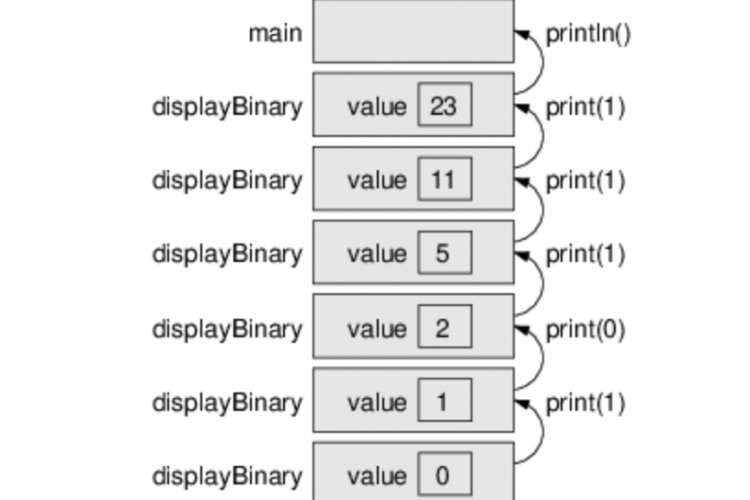
二进制数系统 你可能知道计算机只能存储1和0,这是因为处理器和内存是由数十亿个微小的开关组成的。 值1表示开关打开;值0表示开关关闭。所有类型的数据,无论是整数、浮点、文本、音频、视频或其他数据,都用1和0表示。 幸运的是,我们可以将任何整数表示为二进制数。下表显示了前8个二进制和十进制数字。 Binary Decimal 0 0 1 1 10 2 11 3 100 4 101 5 110 6 1
我们探索一个方法可以做的最神奇的事情之一:调用自身来解决同一问题的较小版本。调用自身的方法称为递归方法。 递归Void方法 考虑以下示例: public static void countdown(int n) { if (n == 0) { System.out.println("Blastoff!"); } else { System.out.println(n); countdown(n -

这篇关于Java中递归的深入教程通过示例、类型和相关概念解释了什么是递归。它还包括递归与迭代: 从Java的早期教程中,我们已经看到了迭代方法,其中我们声明一个循环,然后通过一次获取一个元素以迭代的方式遍历数据结构。 我们还看到了一个条件流,其中我们保留一个循环变量并重复一段代码,直到循环变量满足条件为止。说到函数调用,我们还研究了函数调用的迭代方法。 Java中的递归是什么? 递归是一个函数或方

在Java中,调用自身的方法称为递归方法。这个过程被称为递归。 一个物理世界的例子是将两个平行的镜子相对放置。它们之间的任何对象都将被递归地反射。 递归是如何工作的? 在上面的示例中,我们从main方法内部调用了recurse()方法。(普通方法调用)。在recurse()方法中,我们再次调用相同的recurse方法。这是一个递归调用。 为了停止递归调用,我们需要在方法内部提供一些条件。否则,方法
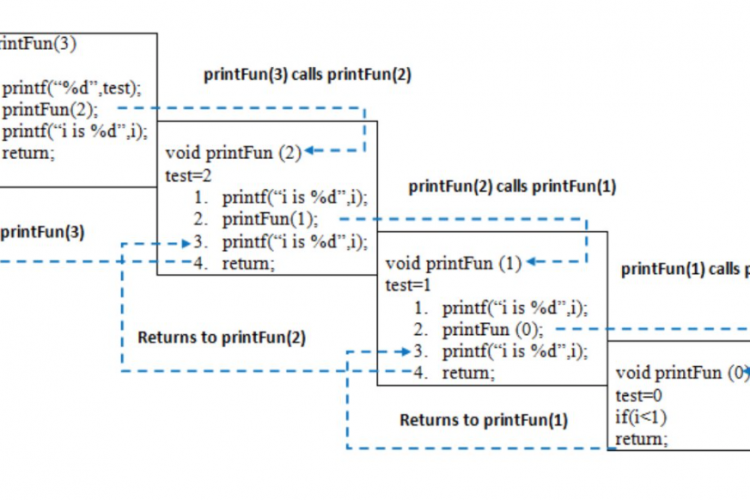
Java中的递归 什么是递归? 函数直接或间接调用自身的过程称为递归,相应的函数称为递归函数。使用递归算法,某些问题可以很容易地解决。这类问题的例子有Hanoi的Towers(TOH)、序/前序/后序树遍历、图的DFS等。 递归中的基本条件是什么? 在递归程序中,给出了基本情况的解,大问题的解用小问题表示。 int fact(int n) { if (n < = 1) // base cas
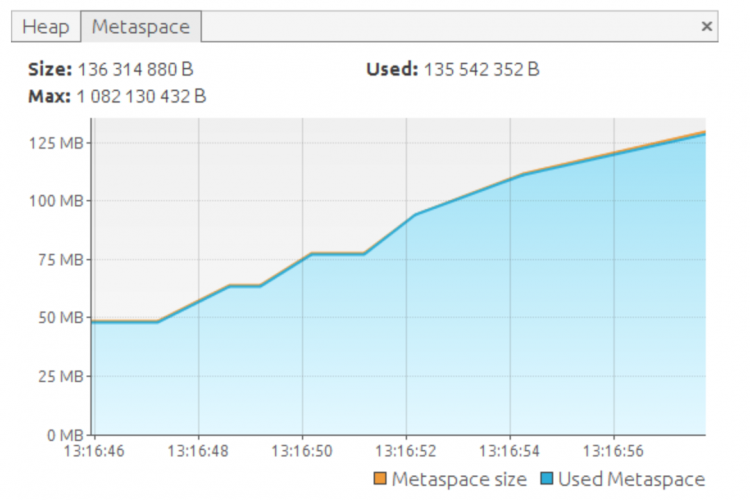
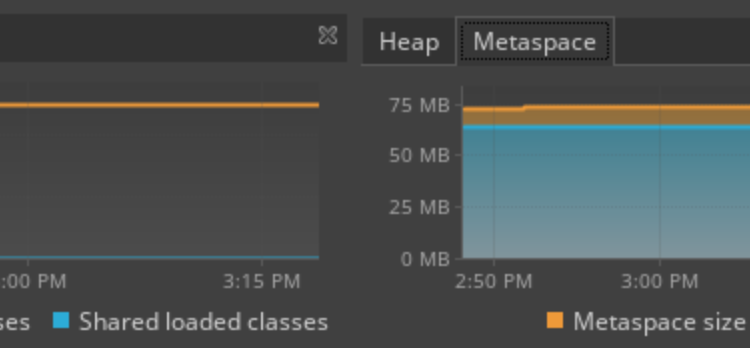
Java8中关于Java7的一个重大变化是用元空间替换永久代。 我们将通过提醒一些关于永久代的信息来开始本文。主要,我们将列出它的缺点,以便更好地理解Java8中用元空间替换它的原因。第二部分将描述更多的新空间在内存中。最后一部分将介绍分析元空间中发生的事情的不同方法。 永久代Permgen缺陷 永久代是一个包含JVM所需数据的池,例如类或方法。当JVM想要创建给定类的新实例时,此数据很有用。通常
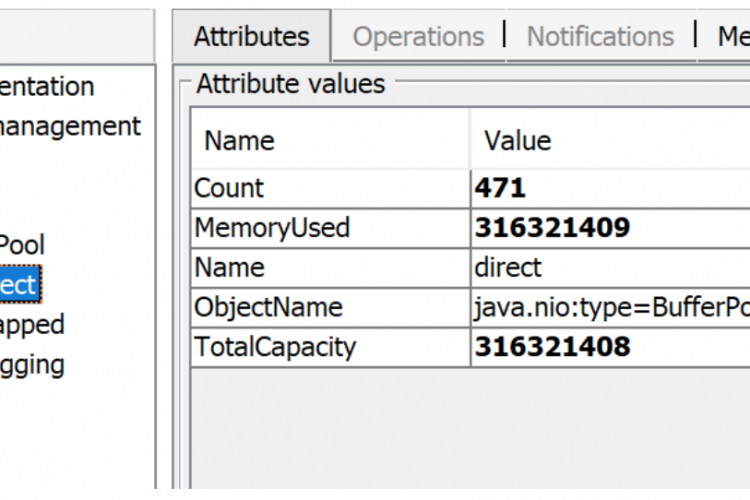
对于我的应用程序,Java进程使用的内存远远大于堆大小。 运行容器的系统开始出现内存问题,因为容器占用的内存远远超过堆大小。 堆大小设置为128MB(-Xmx128m -Xms128m),而容器最多占用1GB内存。正常情况下需要500MB。如果docker容器的限制低于(例如mem_limit=mem_limit=400MB),则进程将被操作系统的内存不足杀手杀死。 那么为什么Java进程比堆占用
一. JVM内存模型 根据JVM规范,JVM内存分为五个部分:虚拟机堆栈、堆、方法区、程序计数器和本地方法堆栈。 虚拟机堆栈:每个线程都有一个私有堆栈,该堆栈在创建线程时创建。堆栈内部是一种称为“堆栈帧”的东西。每个方法将创建一个堆栈帧。堆栈帧存储局部变量表(基本数据类型和对象引用)、操作数堆栈、方法退出和其他信息。堆栈的大小可以固定,也可以动态扩展。当堆栈调用深度大于JVM允许的范围时,将抛出s
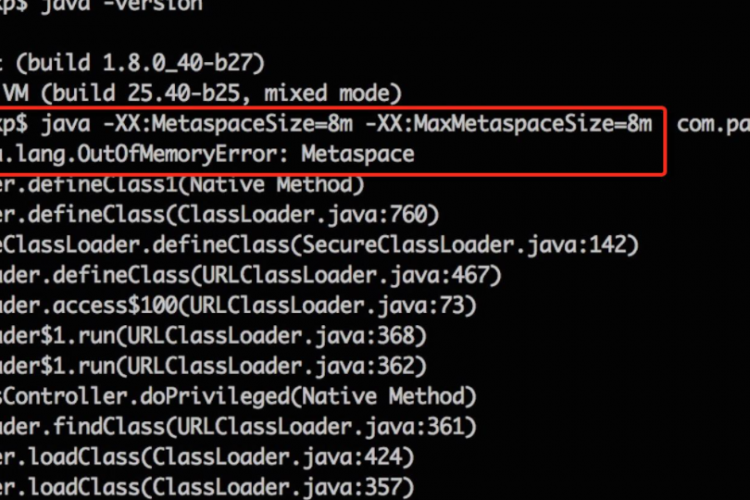
这个java.lang.OutOfMemoryError:Metaspace表示为Java类元数据分配的本机内存量已被耗尽。让我们来看看如何解决这个问题。 一般来说,可以在命令行上设置MaxMetaSpaceSize: java -XX:MaxMetaspaceSize=3200m 你可以试着增加它的价值,看看它是否能解决问题。还要记住,减小Java堆的大小将为MetaSpace提供更多的可用空间
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

更多干货请关注公众号【Java老K】

录制线上真实流量在测试环境进行回放,对比差异
特点:
无代码侵入的数据采集和Mock,支持Spring、Dubbo、Redis、Mybatis等开源框架的录制和回放;
支持各种复杂业务场景的验证:多线程并发、异步回调、写操作等;
欢迎扫码进QQ群交流