文章评分 次,平均分 :
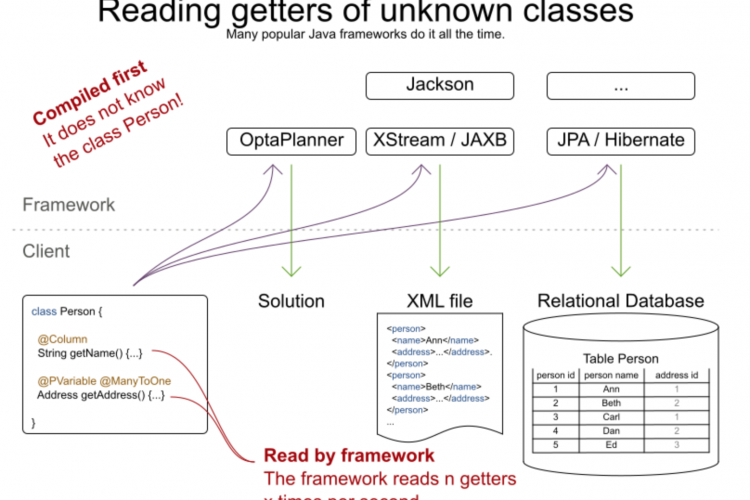
在Java中,普遍认为java.reflect API的性能代价很高。旧的Java版本有巨大的性能开销,而新版本似乎使其处于可接受的范围内。但“可接受”到底是什么意思呢?
这是我在评论一个建议用标准代码替换基于反射的代码的性能评估时提出的问题。由于我们的许多决策不是基于事实而是基于信念,所以我决定执行一些测试来获得Java8中的指标。
测试协议
为了通过一个不受挑战的协议获得实际的度量,我使用了优秀的JMH测试框架。JMH的优势包括:
- Maven已经存在了
- 要进行基准测试的方法只需使用
@benchmark进行注释 - 它处理JVM的预热
- 它还处理在控制台上写入结果的操作
以下是JMH的片段:
@Benchmark
public void executePerformanceTest() {
// Code goes here
}JMH将负责执行上述executePerformanceTest()并负责测量所花费的时间。
反射代码
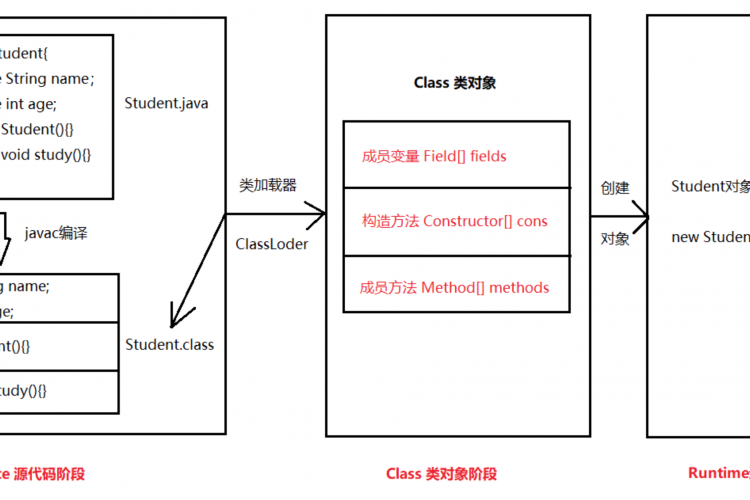
为了强调反射的成本,让我们检查一下使用反射访问属性和不使用反射调用简单getter所需的时间差异。
// With reflection
Field firstName = clazz.getDeclaredField("firstName");
Field lastName = clazz.getDeclaredField("lastName");
Field birthDate = clazz.getDeclaredField("birthDate");
Field.setAccessible(new AccessibleObject[] { firstName, lastName, birthDate }, true);
firstName.get(person);
lastName.get(person);
birthDate.get(person);
// Without reflection
person.getFirstName();
person.getLastName();
person.getBirthDate();检查可能的优化
我想知道不可变的数据结构是否被编译成优化的字节码,从而降低反射的性能开销。
因此,我用两种不同的方式创建了相同的基本数据结构:
- 一个带有无参数构造函数和
setter的变量 - 一个具有最终属性和构造函数初始化的不可变
反射结果
在我的机器上运行测试会产生以下结果:
# Run complete. Total time: 00:26:55
Benchmark Mode Cnt Score Error Units
BenchmarkRun.runImmutableWithReflection thrpt 200 2492673.501 ± 37994.941 ops/s
BenchmarkRun.runImmutableWithoutReflection thrpt 200 26499946.587 ± 242499.198 ops/s
BenchmarkRun.runMutableWithReflection thrpt 200 2505239.277 ± 27697.028 ops/s
BenchmarkRun.runMutableWithoutReflection thrpt 200 26635097.050 ± 150798.911 ops/s
对于对条形图感兴趣的读者(请注意,刻度是线性的):

关于反射性能的测试还可以参考这篇文章:https://javakk.com/733.html
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/768.html

 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论