
奇怪的是,为什么使用“parallelStream()”的代码有时比使用“stream()”的代码慢。
实际上,使用parallelStream()有几个问题。
最重要的是,parallelStream()总是需要执行比按顺序执行更多的实际工作[即stream()]。
在多个线程之间分割工作并合并或组合结果会带来很大的开销。像将短字符串转换为小写字符串这样的用例非常小,与并行拆分开销相比,它们可以忽略不计。

使用多个线程处理数据可能会有一些初始设置成本,例如初始化线程池。这些开销可能会抑制使用这些线程所获得的收益,特别是在运行时已经非常低的情况下。另外,如果有其他线程在运行,后台进程等,或者争用很高,那么并行处理的性能会进一步降低。
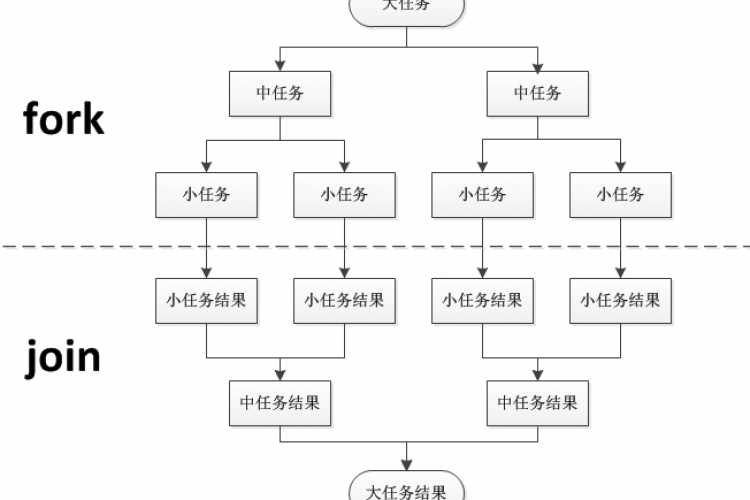
Java中的流实现在默认情况下是顺序的,除非在并行中显式地提到它。当一个流以并行方式执行时,Java运行时将该流划分为多个子流。聚合操作通过并行迭代这些子流来处理这些子流,然后合并这些结果。因此,并行流可用于顺序流具有性能影响的区域
如果你听Oracle的人谈论Java8背后的设计选择,你会经常听到并行性是主要的动机。并行化是lambdas、streamapi等背后的驱动力。让我们看一个流API的例子:
private long countPrimes(int max) {
return range(1, max).parallel().filter(this::isPrime).count();
}
private boolean isPrime(long n) {
return n > 1 && rangeClosed(2, (long) sqrt(n)).noneMatch(divisor -> n % divisor == 0);
}这里,我们有countPrimes方法,它计算介于1和max之间的素数的个数。一个数字流是由range方法创建的。然后将流切换到并行模式;不是素数的数字被过滤掉,剩下的数字被计数。
您可以看到,streamapi允许我们以简洁明了的方式描述问题。此外,并行化只是调用parallel()方法的问题。当我们这样做时,流被分割成多个块,每个块都被独立地处理,结果在最后汇总。由于我们的isPrime方法的实现是非常无效和CPU密集的,我们可以利用并行化和利用所有可用的CPU核。
我们来看另一个例子:
private List<StockInfo> getStockInfo(Stream<String> symbols) {
return symbols.parallel()
.map(this::getStockInfo) //slow network operation
.collect(toList());
}我们有一个股票的输入符号列表,我们必须调用一个缓慢的网络操作,以获得一些关于股票的细节。在这里,我们不处理CPU密集型操作,但是我们也可以利用并行化。并行执行多个网络请求是个好主意。同样,对于并行流来说,这是一个很好的任务,你同意吗?
如果有,请再看前面的例子。有一个很大的错误。你看到了吗?问题是所有并行流都使用公共的fork-join线程池,如果您提交一个长时间运行的任务,那么您将有效地阻塞池中的所有线程。因此,您将阻止使用并行流的所有其他任务。想象一个servlet环境,当一个请求调用getStockInfo()而另一个请求调用countPrimes()。其中一个将阻止另一个,即使它们需要不同的资源。更糟糕的是,不能为并行流指定线程池;整个类装入器必须使用同一个。
让我们用下面的例子来说明:
private void run() throws InterruptedException {
ExecutorService es = Executors.newCachedThreadPool();
// Simulating multiple threads in the system
// if one of them is executing a long-running task.
// Some of the other threads/tasks are waiting
// for it to finish
es.execute(() -> countPrimes(MAX, 1000));
//incorrect task
es.execute(() -> countPrimes(MAX, 0));
es.execute(() -> countPrimes(MAX, 0));
es.execute(() -> countPrimes(MAX, 0));
es.execute(() -> countPrimes(MAX, 0));
es.execute(() -> countPrimes(MAX, 0));
es.shutdown();
es.awaitTermination(60, TimeUnit.SECONDS);
}
private void countPrimes(int max, int delay) {
System.out.println(range(1, max).parallel().filter(this::isPrime).peek(i -> sleep(delay)).count());
}这里,我们模拟系统中的六个线程。他们都在执行CPU密集型任务,第一个“坏”了,发现一个素数后就睡了一秒钟。这只是一个人为的例子;您可以想象一个线程被卡住或执行阻塞操作。
问题是:当我们执行这个代码时会发生什么?我们有六项任务;其中一个要花一整天的时间才能完成,其余的要快得多。毫不奇怪,每次执行代码时,都会得到不同的结果。有时,所有健康的任务都完成了;其他时候,他们中的一些人被困在慢的后面。你想在生产系统中有这样的行为吗?一个坏掉的任务把剩下的应用程序都干掉了?我想不是。
关于如何确保这种事情永远不会发生,只有两种选择。第一种方法是确保提交到公共fork-join池的所有任务不会被卡住,并且不会在合理的时间内完成。但这说起来容易做起来难,特别是在复杂的应用程序中。另一种选择是不使用并行流,而是等到Oracle允许我们指定用于并行流的线程池。
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1914.html


 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论