
使用线程池的Java 8并行流用法
执行并行流时,它在公共ForkJoinPool(ForkJoinPool.commonPool())中运行,由所有其他并行流共享。 有时我们希望在一个单独的专用线程池上并行执行代码,该线程池由特定数量的线程构成。例如,当使用myCollection.parallelStream()时,它并没有为我们提供方便的方法。 我编写了一个小的实用工具(ThreadExecutor类),可以用于此目的。 在下
执行并行流时,它在公共ForkJoinPool(ForkJoinPool.commonPool())中运行,由所有其他并行流共享。 有时我们希望在一个单独的专用线程池上并行执行代码,该线程池由特定数量的线程构成。例如,当使用myCollection.parallelStream()时,它并没有为我们提供方便的方法。 我编写了一个小的实用工具(ThreadExecutor类),可以用于此目的。 在下

奇怪的是,为什么使用“parallelStream()”的代码有时比使用“stream()”的代码慢。 实际上,使用parallelStream()有几个问题。 最重要的是,parallelStream()总是需要执行比按顺序执行更多的实际工作[即stream()]。 在多个线程之间分割工作并合并或组合结果会带来很大的开销。像将短字符串转换为小写字符串这样的用例非常小,与并行拆分开销相比,它们可以

在我们平时开发中或多或少都会遇到需要调用接口来完成一个功能的需求,这个接口可以是内部系统也可以是外部的,然后等到接口返回数据了才能继续其他的业务流程,这就是传统的同步模式。 同步模式虽然简单但缺点也很明显,如果对方服务处理缓慢迟迟未能返回数据,或网络问题导致响应变长,就会阻塞我们调用方的线程,导致我们主流程的耗时latency延长,传统的解决方式是增加接口的超时timeout设置,防止无限期等待。
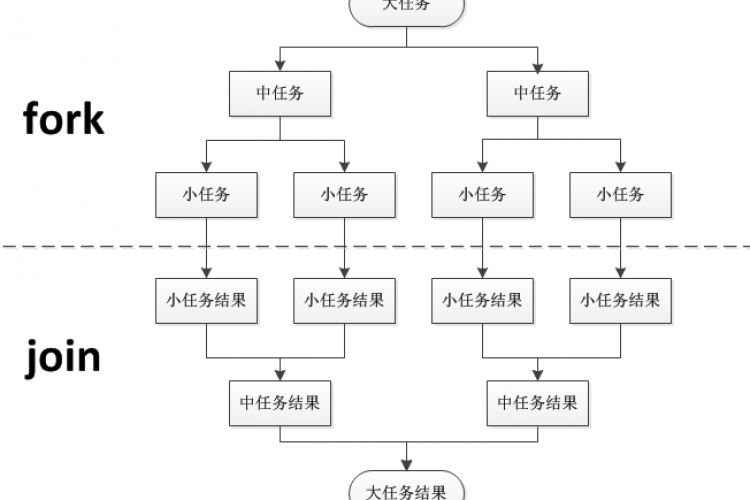
ForkJoinPool线程池最大的特点就是分叉(fork)合并(join),将一个大任务拆分成多个小任务,并行执行,再结合工作窃取模式(worksteal)提高整体的执行效率,充分利用CPU资源。 一. 应用场景 ForkJoinPool使用分治算法,用相对少的线程处理大量的任务,将一个大任务一拆为二,以此类推,每个子任务再拆分一半,直到达到最细颗粒度为止,即设置的阈值停止拆分,然后从最底层的任
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

更多干货请关注公众号【Java老K】

录制线上真实流量在测试环境进行回放,对比差异
特点:
无代码侵入的数据采集和Mock,支持Spring、Dubbo、Redis、Mybatis等开源框架的录制和回放;
支持各种复杂业务场景的验证:多线程并发、异步回调、写操作等;
欢迎扫码进QQ群交流