今天,我将向您展示调优Jenkins Java参数如何设置,使您的主控程序更加响应和稳定,尤其是在堆大小较大的情况下。
- 基本信息:-服务器
-XX:+alwaysspretouch - GC日志记录:
-Xloggc:$JENKINS_HOME/GC-%t.log-XX:NumberOfGCLogFiles=5-XX:+UseGCLogFileRotation-XX:GCLogFileSize=20m-XX:+PrintGC-XX:+PrintGCDateStamps-XX:+PrintHeapAtGC-XX:+PrintGCCause-XX:+PrintTenuringDistribution-XX:+PrintReferenceGC-XX:+PrintAdaptiveSizePolicy - G1 GC设置:
-XX:+UseG1GC-XX:+ExplicitGCInvokesConcurrent -XX:+ParallelRefProcEnabled -XX:+UseStringDeduplication -XX:+UnlockDiagnosticVMOptions -XX:g1SummarySetStatsPeriod=1 - 堆设置:将最小堆大小(
-Xms)至少设置为最大大小(-Xmx)的1/2。
现在,让我们看看它们是从哪里来的!我们将在这里集中讨论垃圾收集(GC),并快速深入地挖掘,以寻找黄金。
因为性能调优是数据驱动的,所以我将使用实际数据,选择三个我帮助支持的非常大的Jenkins实例。
症状:用户报告Jenkins实例定期挂起,处理通常快速的请求需要几秒钟。我们甚至可以看到与Jenkins master(构建代理等)通信的系统发生锁定或超时。在长时间的重载下,用户可能会报告詹金斯运行缓慢。应用程序监视显示,在锁定期间,所有或大部分CPU内核都已完全加载,但没有足够的活动来证明这一点。进程和JStack转储将显示最活跃的Java线程正在进行垃圾收集。
对于实例A,他们遇到了这个问题。他们的Jenkins Java参数非常接近默认值,除了调整堆大小:
- 最大24 GB堆,4 GB初始,默认GC设置(ParallelGC)
- 设置了一些标志(其中一些作为默认设置):
-XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:+ReduceSignalUsage -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation
启用垃圾收集(GC)日志记录后,我们可以看到以下粗略统计信息:

深入研究,我们得到GC暂停持续时间图表:

关键数据:
- 吞吐量:99.64%(执行应用程序代码、不执行垃圾收集所用时间的百分比)
- 平均气相色谱时间:348毫秒!
- 2秒以上GC循环:36次(2.7%)
- 小/全气相色谱平均时间:263 ms/2.803秒
- 对象创建和提升速率:42.4 MB/s和1.99 MB/s
说明:
正如您所看到的,年轻的GC周期非常快速地清除新创建的垃圾,但是更深层的旧一代GC周期运行得非常慢:2-4秒。这就是我们的问题发生的地方。默认的Java垃圾收集算法(parallellgc)在必须收集垃圾时暂停所有内容(通常称为“stop The world pause”)。在这段时间里,詹金斯完全停了下来:通常情况下(有一小堆),这些停顿时间太短,不会成为一个问题。对于4GB或更大的堆,所需的时间变得足够长,以至于成为一个问题:在短窗口中需要几秒钟,而在较长的时间间隔内,您偶尔会看到更长的暂停(几十秒或几分钟)
这是用户可见的挂起和锁定发生的地方。它还为那些构建/部署任务增加了显著的延迟。在负载较重的情况下,系统甚至在一个完整的GC周期内经历30秒以上的挂起。这段时间足以触发网络超时(或内部Jenkins线程超时),并导致更大的问题。
幸运的是有一个解决方案:并发低暂停垃圾收集算法、并发标记清除(CMS)和垃圾优先(G1)。这些方法试图与应用程序线程同时执行大部分垃圾回收,从而缩短暂停时间(在额外占用CPU方面稍有代价)。我们将把重点放在G1上,因为它将成为java9中的默认值,并且是大堆大小的官方建议。
让我们看看当有人在一个类似大小的Jenkins主机上使用G1时,实例B(17gb堆)会发生什么:
它们的设置:
- 最大堆容量为16 GB,初始大小为0.5 GB
- Java标志(除G1外,大多数是默认值):
-XX:+UseG1GC-XX:+UseCompressedClassPointers-XX:+useCompressedDoops
以及GC日志分析:

关键数据:
- 吞吐量:98.76%(不算太好,但还是稍微慢了一点)
- 平均气相色谱时间:128毫秒
- 气相色谱循环超过2秒:11,0.27%
- 小/全气相色谱平均时间:122毫秒/1秒232毫秒
- 对象创建和提升速率:132.53 MB/s和522 KB/s
好吧,好得多:一个小30%的堆可能会有一些改进,但不会像我们看到的那么多。大多数GC暂停都在2秒以下,但是我们有11个异常值—长的2-12秒的完整GC暂停。这些都是令人不安的;我们稍后将更深入地探讨它们的原因。首先,让我们看一下全局,然后看一下Jenkins在g1gc中的行为。
使用实例C进行G1垃圾回收(24 GB堆):
它们的设置:
- 最大24 GB堆,24 GB初始堆,最大2 GB元空间
- 一些自定义标志:
-XX:+UseG1GC-XX:+AlwaysPreTouch-XX:+UseStringDeduplication-XX:+UseCompressedClassPointers-XX:+UseCompressedOops
显然,他们已经做了一些垃圾收集优化和优化。总是使用预零来分配堆页,而不是等到它们第一次被使用。特别是对于较大的堆大小,建议这样做,因为它以稍微慢一点的启动时间换取更好的运行时性能。还要注意,它们预先分配了整个堆。这是一个常见的优化。
它们还启用了StringDeduplication,这是java8update20中引入的G1选项,可以透明地用指向原始字符的指针替换相同的字符数组,从而减少内存使用(并提高缓存性能)。想想String.intern()在垃圾收集过程中悄然发生。这是一个添加到普通GC周期上的并发操作,因此它不会暂停应用程序。我们稍后再看它的影响。
看一下基础知识:

与实例B类似,但它被绝对数量的点数所隐藏(这里的时间较长,1个月)。那些偶尔出现的完全GC异常值也会出现!
关键数据:
- 吞吐量:99.93%
- 平均气相色谱时间:127毫秒
- 2秒以上GC循环:235(1.56%)
- 小/全气相色谱平均时间:56毫秒/3.97秒
- 对象创建和提升速率:34.06 MB/s和286 kb/s
总体上与实例B相当相似:大约100毫秒的GC周期,所有次要的GC周期都非常快。对象提升率听起来很相似。
还记得那些随机的长时间停顿吗?
让我们找出是什么原因造成的,以及如何消除它们。实例B有11个超长暂停异常值。让我们通过在GCViewer中打开GC日志来获得更多细节。这个工具提供了大量的信息。太多了,事实上——我更喜欢用GCEasy.io版除非需要。由于GC日志不包含有害信息(与堆转储或某些堆栈跟踪不同),web应用程序是一个很好的分析工具。

我们关心的是在完整的GC时间中间(突出显示)。看看它们比年轻的和并发的GC循环长多少(2秒或更少)?
我刚才撒了谎-对不起!对于并发垃圾收集器,实际上有3种模式:年轻GC、并发GC和完全GC。Concurrent GC用与应用程序并行运行的更快的并发操作取代了并行GC中的Full-GC模式。但在少数情况下,我们将被迫回到非并发的完整GC操作,该操作将使用串行(单线程)垃圾收集器。这意味着,即使我们有30多个CPU核心,也只有一个在工作。这就是发生在这里的事情,在一个大的堆,多核系统上,它是低的。有多慢?280MB/s,而实例B为12487MB/s(例如实例C,两者之间的差异也约为50:1)。
是什么触发了完整的GC而不是并发的:
- 显式调用垃圾回收System.gc() (最常见的罪魁祸首,往往难以追查)
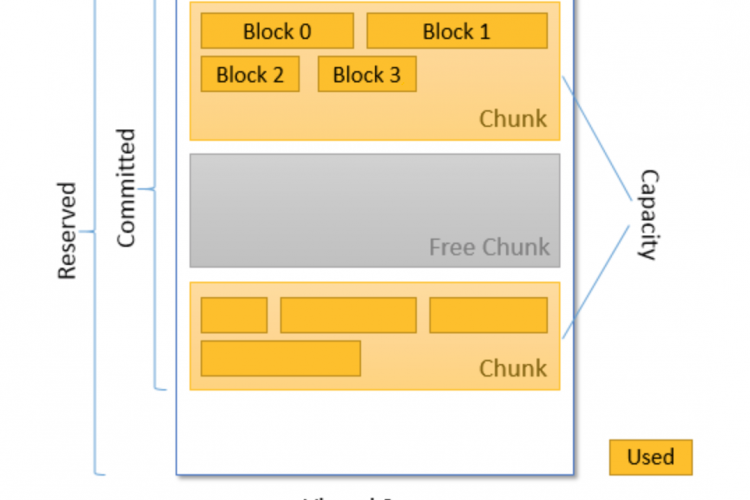
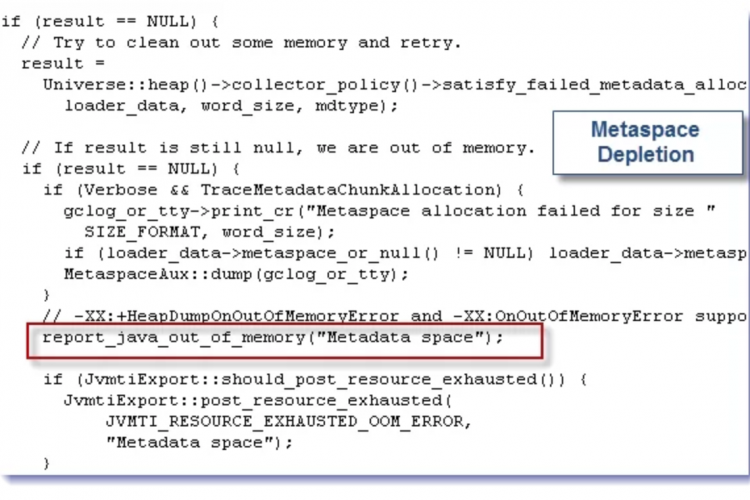
- Metadata GC Threshold:Metaspace(主要用于类数据)已达到定义的大小以强制垃圾回收或增加垃圾回收。文档对此很糟糕,堆栈溢出将是您的朋友。
- 并发模式失败:并发GC无法以足够快的速度完成,无法跟上应用程序正在创建的对象(前面有JVM参数触发Concurrent GC)
我们怎么解决这个问题?
对于显式GC:
-XX: +DisableExplicitGC将关闭由垃圾回收(). 通常在生产中设置,但下面的选项更安全。- 我们可以用
-XX:+ExplicitGCInvokesConcurrent来触发一个并发GC来代替完整的GC,这将把显式调用作为执行更深入清理的提示,但性能成本更低。
对那些使用过CMS的人来说,你可能已经使用过CMS选项-XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses——这是它所说的。这个选项将在G1中悄然失败,这意味着您仍然可以看到整个GC周期中非常长的暂停,就好像它没有设置一样(不会生成警告)。我正试图为这个问题记录一个JVM错误。
对于元数据GC阈值:
将初始元空间增加到最终大小,以避免调整大小。例如:-XX:MetaspaceSize=500M
实例C在显式GC调用中也遇到了同样的问题,几乎所有的异常值(235个异常值中的230个)都是由缓慢的、非当前的完整GC周期(全部来自显式)引起的垃圾回收System.gc() 个调用,因为它们优化了metaspace):

下面是如果删除显式垃圾回收System.gc()调用,假设它们将与其他并发GC暂停混合(不是100%准确,但是一个很好的近似值):
实例B:

开始时的几个长的完整GC周期来自于元空间扩展——可以通过增加初始元空间大小来删除它们,如上所述。钉子?这时我们要调整Java堆的大小,内存压力很大。您可以通过将最小/初始堆设置为最大值的至少一半来避免这种情况,以限制调整大小。
统计信息:
- 吞吐量:98.93%
- 平均气相色谱时间:111毫秒
- GC循环超过2秒:3
- 次要和完全或并发GC平均时间:122毫秒/25毫秒(是的,比次要时间快!)
- 对象创建和提升速率:132.07 MB/s和522 kB/s
实例C:

统计信息:
- 吞吐量:99.97%
- 平均气相色谱时间:56毫秒
- GC循环超过2秒:0(!!!)
- 次要和完全或并发GC平均时间:56毫秒和10毫秒(是的,比次要时间快!)
- 对象创建和提升速率:33.31 MB/s和286 kB/s
- 另一点:GCViewer声称GC性能为128gb/s(这不是不合理的,我们通常在100毫秒以下清除~10gb的年轻一代)
好吧,所以我们已经驯服了最坏情况下的长时间停顿!
我们看到的那些长时间的GC停顿呢?
好了,现在我们进入了最后阶段!我们已经用并发收集驯服了老一代的GC暂停,但是那些较长的年轻一代暂停呢?让我们在GCViewer中再次查看不同阶段和原因的统计信息。

我们看到了罪魁祸首:G1垃圾回收的备注阶段。这个Stop The World 停止世界阶段确保我们已经识别了所有的活动对象,并处理了引用(更多信息)。
让我们看一个示例执行以获取更多信息:
2016-09-07T15:28:33.104+0000:26230.652:[GC备注26230.652:[GC参考程序,1.7204585秒],1.7440552秒]
[次数:用户=1.78 sys=0.03,实数=1.75秒]
这在GC日志中是很典型的:最长的暂停花费在引用处理上。这并不奇怪,因为Jenkins在内部大量使用引用进行缓存,尤其是弱引用,并且默认的引用处理算法是单线程的。请注意,用户(CPU)时间与实时相匹配,如果使用多个内核,则会更高。
因此,我们添加GC标志-XX:+ParallelRefProcEnabled,它使我们能够更有效地使用多个核心。
基于实例C进一步优化年轻一代GC:
回到GCViewer,我们继续,看看使用GC(例如实例C)有什么耗时。

这很好,因为大部分时间都是在清理垃圾(疏散暂停)。但1.8秒的停顿看起来很奇怪。让我们看一下原始GC日志中最长的暂停:
2016-09-24T16:31:27.738-0700: 106414.347: [GC pause (G1 Evacuation Pause) (young), 1.8203527 secs]
[Parallel Time: 1796.4 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 106414348.2, Avg: 106414348.3, Max: 106414348.6, Diff: 0.4]
[Ext Root Scanning (ms): Min: 0.3, Avg: 1.7, Max: 5.7, Diff: 5.4, Sum: 14.0]
[Update RS (ms): Min: 0.0, Avg: 7.0, Max: 19.6, Diff: 19.6, Sum: 55.9]
[Processed Buffers: Min: 0, Avg: 45.1, Max: 146, Diff: 146, Sum: 361]
[Scan RS (ms): Min: 0.2, Avg: 0.4, Max: 0.7, Diff: 0.6, Sum: 3.5]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.2]
[Object Copy (ms): Min: 1767.1, Avg: 1784.4, Max: 1792.6, Diff: 25.5, Sum: 14275.2]
[Termination (ms): Min: 0.3, Avg: 2.4, Max: 3.5, Diff: 3.2, Sum: 19.3]
[Termination Attempts: Min: 11, Avg: 142.5, Max: 294, Diff: 283, Sum: 1140]
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.4, Diff: 0.3, Sum: 0.8]
[GC Worker Total (ms): Min: 1795.9, Avg: 1796.1, Max: 1796.2, Diff: 0.3, Sum: 14368.9]
[GC Worker End (ms): Min: 106416144.4, Avg: 106416144.5, Max: 106416144.5, Diff: 0.1]几乎整个时间(1.820中的1.792秒)都在遍历活动对象并复制它们。等等,统计数据行显示的是:
- Eden 伊甸园:13.0G(13.0G)->0.0B(288.0M)
- Survivors 幸存者:1000.0M->936.0M
- Heap 堆:20.6G(24.0G)->7965.2M(24.0G)]
很遗憾,我们用掉了13 GB(!!!)一下子就把新分配的垃圾压缩了!怪不得这么慢。我不知道我们怎么积累了这么多。。。

我们最初设置了24gb的堆,每个小GC清除了年轻一代的大部分内容。好吧,所以我们留出了大量的空间来收集垃圾,这意味着GC周期更长。我们可以通过设置-XX:maxgcpausemilis标志来控制GC暂停时间,但是如果我们查找,大多数暂停都在250毫秒的默认值之下。对于詹金斯来说,这个硬件似乎工作得很好。如果年轻一代GC暂停时间也太长,我们可以考虑稍微减小堆大小,但首先应该让G1尝试调整自己以适应暂停时间。
一些最终设置
我们提到过StringDeduplication在实例C上启用,有什么影响?这只会在经过几代的字符串上触发(我们的大多数垃圾没有),它可以使用的CPU时间有限制,并替换对其不可变的支持字符数组的重复引用。更多信息,请看这里。所以,我们应该用一点CPU时间来换取更高效的内存(类似于字符串内接)。
一开始,这会产生巨大的影响:
[GC concurrent-string-deduplication, 375.3K->222.5K(152.8K), avg 63.0%, 0.0 024966 secs]
[GC concurrent-string-deduplication, 4178.8K->965.5K(3213.2K), avg 65.3%, 0 .0272168 secs]
[GC concurrent-string-deduplication, 36.1M->9702.6K(26.6M), avg 70.3%, 0.09 65196 secs]
[GC concurrent-string-deduplication, 4895.2K->394.9K(4500.3K), avg 71.9%, 0 .0114704 secs]这个峰值平均约为90%:
运行一个月后,影响较小—许多可以消除重复的字符串包括:
[GC concurrent-string-deduplication, 138.7K->39.3K(99.4K), avg 68.2%, 0.0007080 secs]
[GC concurrent-string-deduplication, 27.3M->21.5M(5945.1K), avg 68.1%, 0.0554714 secs]
[GC concurrent-string-deduplication, 304.0K->48.5K(255.5K), avg 68.1%, 0.0021169 secs]
[GC concurrent-string-deduplication, 748.9K->407.3K(341.7K), avg 68.1%, 0.0026401 secs]
[GC concurrent-string-deduplication, 3756.7K->663.1K(3093.6K), avg 68.1%, 0.0270676 secs]
[GC concurrent-string-deduplication, 974.3K->17.0K(957.3K), avg 68.1%, 0.0121952 secs]不过,它的使用成本很低:平均而言,每个重复数据消除周期需要8.8毫秒,并删除2.4 kB的重复数据。中值耗时1.33毫秒,从旧代中删除17.66 kB。每个周期的变化很小,但总的来说,它加起来很快——在高负载时期,这可以节省数百兆字节的数据。但相对于多GB的堆来说,这还是很小的。
结论:字符串重复数据消除技术使用起来相当便宜,并且减少了Jenkins所需的稳态内存。这为年轻一代腾出了更多的空间,并且应该通过删除重复对象来减少GC时间。我认为它值得打开。
软引用刷新:Jenkins使用软引用缓存构建记录和管道流节点。唯一的保证是它们将被删除,而不是导致OutOfMemoryError。。。然而,Java应用程序可能会在这之前很久就从内存压力中缓慢爬行。有一个选项根据时间和空闲内存向JVM提供提示,由-XX:SoftRefLRUPolicyMSPerMB(默认值1000)控制。软引用在上一次触摸后经过了这么多毫秒后才有资格进行垃圾回收。。。每MB未使用的堆(与最大值相比)。被引用的对象不计入该目标。因此,在10GB的堆空闲空间和默认的1000ms设置下,软引用可以在大约2.8小时内保持。
如果系统不断地分配更多的软引用,它可能会触发大量的GC活动,而不是清除软引用。有关更多详细信息,请参阅打开的bug JDK-6912889。
如果Jenkins消耗了过多的老一代内存,那么可以通过将-XX:SoftRefLRUPolicyMSPerMB从默认值(1000)减少到更小的值(比如10-200),从而使软引用更容易刷新。缺点是软引用通常用于加载相对昂贵的对象,例如延迟加载的构建记录和管道流节点数据。
注意事项
G1与CMS:G1在jre7的后期版本中可用,但不稳定且速度较慢。如果你使用它,你必须使用jre8,而且越晚发布越好(它有很多补丁)。谷歌搜索会显示出2014年左右可怕的g1vscms基准:这些可能最好被忽略,因为G1的实现当时还不成熟。CMS的应用可能仍然有一个利基,特别是在中型堆(1-3GB)或设置已经调整的地方。通过适当的调优,对于Jenkins(它主要生成短期垃圾)来说,它仍然可以表现得很好,但是CMS最终会遭受堆碎片的困扰,需要一个缓慢的、非并发的完整GC来清除这一问题。它还需要比G1更多的调谐。
一般GC调优注意事项:没有一个单独的设置适合所有人。我们避免调整在这里没有有力证据的设置,但当然还有许多其他设置需要调整。但是,在没有证据的情况下,你不应该改变它们,因为它会导致意想不到的副作用。我们前面启用的GC日志将收集这些证据。作为进一步调优的一个可能候选的唯一设置是G1区域大小(太小,并且有许多庞大的对象分配,这会影响性能)。在更小的系统上运行时,我看到了一些证据表明区域不应该小于4MB,因为有1-2MB的对象是有规律地分配的——但是在没有更多数据的情况下,这是不够的。
在调整Jenkins GC之前我应该做些什么:
如果您看过stephenconnolly精彩的Jenkins World演讲,您就会知道大多数Jenkins实例可以而且应该使用4gb或更少的已分配堆,甚至可以达到非常大的大小。您将希望打开GC日志记录(如上所述)并查看几个星期内的统计数据(记住GCeasy.io版). 如果你没有看到周期性较长的停顿时间,你可能没事。
对于这篇文章,我们假设我们已经为詹金斯完成了基本的绩效工作:
- Jenkins运行在快速的,固态硬盘备份存储。
- 我们已经为您的作业设置了构建轮换,以删除旧版本,使它们不会堆积起来。
- 已对文件夹禁用天气列。
- 所有生成/部署都在生成代理(以前是从系统)上运行,而不是在主代理上运行。如果主服务器分配了执行器,则它们将专门用于备份任务。
- 我们已经验证了Jenkins确实需要大的堆大小,并且不容易被分成单独的主堆。
如果没有,我们需要在研究GC调优之前先这样做,因为那样会产生更大的影响。
结论
我们从:
- 平均350毫秒暂停(糟糕的用户体验),包括频率较低的2+第二代暂停
- 平均停顿时间约为50毫秒,几乎都在250毫秒以下
- 通过字符串重复数据消除减少了总内存占用
怎么做:
- 使用垃圾优先(Garbage First,G1)垃圾回收,这对于Jenkins来说通常表现得很好。通常有足够的空闲CPU时间来支持并发运行。
- 确保明确垃圾回收()和元空间大小调整不会触发完整的GC,因为这可能会触发非常长的暂停
- 为Jenkins打开并行引用处理以充分使用所有CPU核心。
- 使用字符串重复数据消除,这为詹金斯赢得了一场漂亮的胜利
- 启用GC日志记录,如果需要,可以将其用于下一级别的优化和诊断。
仍然有一点不可预测,但是使用适当的设置可以提供一个更加稳定、响应迅速的CI/CD服务器。。。甚至高达20GB的堆大小!
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/865.html
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论