
Apache Pulsar(孵化)是一个企业级的发布-订阅(aka pub-sub)消息系统,最初由雅虎开发。Pulsar于2016年末首次开放源码,目前正在Apache软件基金会的赞助下进行孵化。在雅虎,Pulsar已经生产了三年多,为雅虎等主要应用提供了动力!
Pulsar概念和术语
将数据输入Pulsar的应用程序称为生产者,而使用Pulsar数据的应用程序称为消费者。消费者应用程序有时也被称为订户。遵循一般的pub-sub模式,主题是Pulsar的核心资源。松散地说,主题表示生产者向其中附加数据和消费者从中提取数据的通道。如下图所示。

Pulsar从头开始构建,以支持多租户用例。Pulsar支持两个多租户特定的资源来启用多租户:属性和名称空间。属性表示系统中的租户。举个例子,想象一个Pulsar集群被部署来支持各种各样的应用程序(就像雅虎的Pulsar一样)。在Pulsar集群中,每个属性可以代表企业中的一个团队、一个核心特性或一个产品线,仅举几个例子。每个属性可以依次包含多个名称空间,例如每个应用程序或用例一个名称空间。命名空间可以包含任意数量的主题。这个层次结构如下图所示。

namespace是Pulsar的基本管理单元。在命名空间级别,您可以设置权限、微调复制设置、跨集群管理消息数据的地理复制、控制消息过期以及执行关键操作。命名空间中的所有主题都继承相同的设置,这为同时配置多个主题提供了强大的管理杠杆。根据命名空间可见的级别,有两种不同类型的命名空间:
Local—本地命名空间仅对定义它的集群可见。Global-在这种情况下,命名空间在多个集群中可见,无论是在数据中心内还是在地理位置上分离。这取决于是否在命名空间的设置中跨集群启用复制。
虽然本地和全局名称空间在范围上有所不同,但它们都可以通过适当的设置在不同的团队或不同的组织中共享。一旦提供了写入命名空间的权限,应用程序就可以写入命名空间中的任何主题。如果某个主题不存在,则在生产者第一次写入时会动态创建该主题。
如前所述,每个名称空间可以有一个或多个主题;每个主题可以有多个订阅;并且每个订阅都被设置为保留和接收在该主题上发布的所有消息。为了给应用程序提供更大的灵活性,Pulsar支持在同一主题上共存的三种不同类型的订阅:
- 独占订阅-对于这种类型的订阅,在任何给定时间只能有一个使用者。
- 共享订阅—在这种情况下,多个使用者可以附加到同一订阅,每个使用者将收到一小部分消息。
- 故障转移订阅—使用故障转移订阅,允许多个使用者连接到一个主题,但在任何给定时间只有一个使用者将接收消息。其他使用者只有在当前接收使用者失败时才开始接收消息。
三种不同类型的订阅如下图所示。订阅提供了一个主要的优势,因为它们将消息的生成和使用方式解耦。由于支持不同类型的订阅,Pulsar在不增加开发复杂性的情况下提供了应用程序的弹性。

数据分区
输入到主题中的数据可以从几兆字节(小数据)到几兆字节(“大数据”)。这意味着主题在某些情况下需要能够保持稳定的低吞吐量,而在其他情况下则需要能够保持非常高的吞吐量,这取决于使用者的数量。那么,当一个主题需要高吞吐量,而另一个主题需要低吞吐量时会发生什么呢?为了解决这个问题,Pulsar允许您在一个主题中切分数据并将其存储在多台机器上。这些数据碎片称为分区。
跨一组机器使用分区是跨多个节点处理大量数据的常用方法,同时还可以实现高吞吐量。默认情况下,Pulsar主题被创建为非分区主题,但是您可以非常轻松地使用简单的CLI命令或API调用创建分区主题并为它们分配特定数量的分区。
创建分区主题时,Pulsar会自动对数据进行分区,并确保使用者和生产者可以不受分区影响。也就是说,使用单个主题编写的应用程序在对主题进行分区时仍然可以工作,没有代码更改,这使得分区成为纯粹的管理问题,而不是应用程序级别的问题。
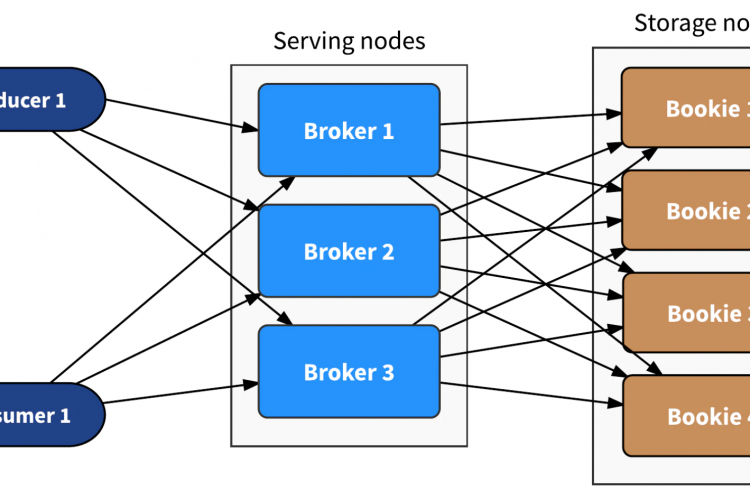
在Pulsar中,主题的划分由一个称为代理的过程来处理;脉冲星群中的每个节点都运行自己的代理。下图详细显示了代理节点如何处理分区。

虽然应用程序可以在不更改代码的情况下利用分区,但是有一些附加的钩子可以帮助您在分区和可用使用者之间实现更好的数据分发。Pulsar通过允许您选择路由策略来控制消息如何路由到特定分区。有四种基本路由策略:
- 单个分区—生产者选择一个随机分区,并仅将数据路由到该分区。此模型保留了非分区主题提供的相同保证,但在许多生产者发布到某个主题时可能会有所帮助。
- 循环分区—在这种情况下,生产者以循环方式将数据均匀地分布在所有分区上。第一条消息进入第一个分区,第二条消息进入第二个分区,依此类推。
- 哈希分区——在这种情况下,每条消息都携带一个密钥。分区的选择基于对消息键应用哈希函数所生成的值。哈希分区将保证基于密钥的排序。
- 自定义分区—这里,生产者使用一个自定义函数来获取消息并生成分区号。然后将消息定向到该分区。自定义分区使应用程序能够完全控制分区逻辑。
耐久性
一旦Pulsar代理接收并确认从某个主题的制作者那里接收到的数据,它就需要确保数据在任何情况下都不会丢失。与其他几种消息传递系统不同,Pulsar使用apachebookkeeper实现了持久性,它提供了低延迟持久性存储。当Pulsar代理接收到消息时,它会将消息数据发送到多个BookKeeper节点(基于复制因子)。这些节点将数据写入预写日志,并将副本写入内存。在节点发出确认之前,日志被强制写入稳定的存储器。通过强制将日志写入存储器,即使在发生断电的情况下,数据也会被保留。由于Pulsar broker向多个BookKeeper节点写入数据,因此只有当数据成功写入写入仲裁时,它才会向生产者发送确认。因此,Pulsar能够确保即使在存在硬件故障、网络分区和其他故障状态的情况下也不会丢失数据。
生产验证
Pulsar目前为雅虎的主要应用提供动力,如邮件、金融、体育、广告和雅虎的分布式键值服务Sherpa。许多用例需要强大的持久性保证,例如零数据丢失,同时也满足严格的性能要求。Pulsar于2015年开始部署,目前由雅虎大规模运营。
- 部署在全球10多个数据中心,具有完整的mesh复制功能
- 每天处理超过1000亿条已发布的消息
- 提供超过140万个主题
- 在整个服务中提供小于5毫秒的平均发布延迟
结论
在这篇文章中,我们简单介绍了Apache Pulsar 背后的概念,并展示了Pulsar如何通过在向用户发送确认之前提交数据来实现持久性,如何通过对数据进行分区来实现高吞吐量,等等。
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1865.html

 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论