虽然我们可以在堆转储中的dump文件找到大对象,但只有在OutOfMemoryError出现时,它们才会给出泄漏的指示。为了在事后分析期间有机会找到一些东西,应该始终使用JVM参数-XX:+HeapDumpOnOutOfMemoryError。
但并不是所有的泄漏都会导致OutOfMemoryError并产生转储dump文件,否则需要很长时间才能发生。例如,服务器和JVM甚至可以定期重启以进行部署或解决内存问题。
要找到缓慢增长的内存泄漏,我们必须执行更复杂和耗时的分析。我们可以使用多个转储,这些转储会随着时间的推移而展开。虽然它们理论上允许我们识别不断增长的结构,但在实践中会很乏味,因为多个转储之间的差异将主要是正常波动,这使得很难发现相关的三角洲。您已经知道了内存泄漏产生的用例,然后可以在转储之间调用这些用例。但最大的问题可能是在生产环境中创建转储是不可取的,因为它可能会使系统挂起几秒钟到几分钟,这取决于堆的大小。
更好的解决方案是在应用程序运行时监视堆和堆中的相关对象。通过这样做,我们可以跟踪每一个结构,并得到通知时,一些东西不断增长的时间。而且由于应用程序仍在正常运行,我们也可以很容易地获得与泄漏交互的代码的信息。使用堆转储根本不可能做到这一点,因为它们不包含有关代码的信息。
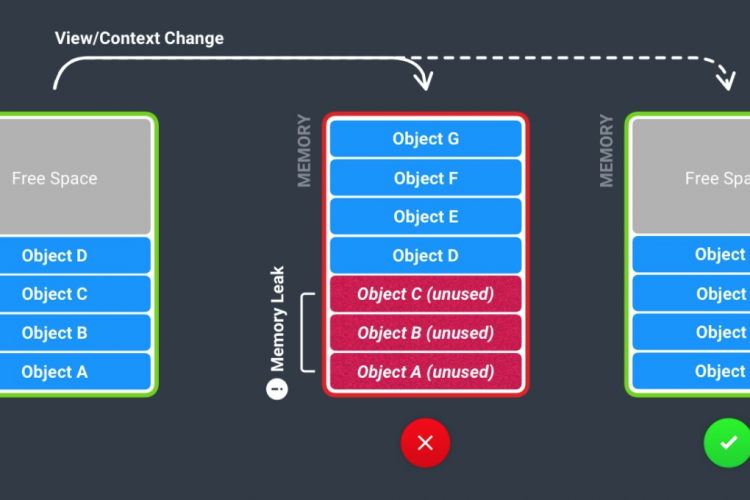
内存泄露概念
堆的运行时分析模式非常简单:
- 查找应用程序创建的所有对象。
- 追踪这些物体并记录它们的大小。
- 警惕任何“异常”行为。
- 提供诊断的内容和调用代码。
不幸的是,每一点在实践中都会带来很多问题。因此,这一概念只有少数几个实现。找到所有相关的物体并不是一件容易的事。在演示应用程序中,对象的数量是可以管理的,而在实际应用程序中,对象的数量是数百万。我们怎样才能在这些复杂的结构上高效地存储数据?什么是“不正常”行为?有没有我们认为“正常”的物体的大小和寿命?
实现
作为这个概念的一个例子,我将展示APM解决方案AppDynamics的泄漏检测功能。泄漏检测的唯一其他实现是Introscope leak Hunter,据我所知,它不使用堆转储。
假设
正如您所猜测的,上面概述的解决方案无法实际实现。我们需要用简单的假设来简化问题。幸运的是,对于任何Java程序,都可以做很多假设。例如,垃圾收集器使用对象的典型年龄分布来处理不同的代
AppDynamics正在进行以下假设:
- 不需要监视所有对象。经验表明,大多数内存泄漏都是由于将数据放入集合类型结构(如列表和映射)中,而不是稍后从中删除数据而导致的。自定义缓存实现是一个非常典型的例子。因此,AppDynamics只监视这些类。
- 我们不需要查看未使用的集合,例如应用程序服务器在启动时创建的内部结构。我们只需要与代码交互的结构。
- 从这些活动集合中,我们只需要监视那些包含相关数量对象的集合。因为我们在寻找漏洞,这个数字必须随着时间的推移而增加。
- 那些长时间的活动集合可能是泄漏,但要成为代码稳定性的相关问题,该集合必须控制大量内存。
- 所有这些因素都适用于较长的一段时间。
AppDynamics使用类似的过程来查找泄漏。因此,它将对受监视的JVM的影响降至最低。此外,AppDynamics使用精心设计的算法高效地计算对象树大小,开销非常低,即使在高负载下也是如此。然而,内存分析将始终连接到一个更高的开销。
我的开源集合分析器
因为AppDynamics是一个商业解决方案,所以我想尝试实现这样一个内存泄漏查找器。
您可以在Github上找到我的基本Java内存分析器版本。
其基本思想非常容易实现。我的分析器只使用两个类进行编码。
采集分析视角
我做了与AppDynamics类似的假设,只看集合。如果我想在这里添加任何类:
@Before(" call(* java.util.Map.put(..)) &&
!this(de.codecentric.performance.memory.CollectionAnalyzerAspect)")
public void trackMapPuts(final JoinPoint thisJoinPoint) {
Map target = (Map) thisJoinPoint.getTarget();
CollectionStatistics stats = getStatistics(target);
stats.recordWrite(getLocation(thisJoinPoint));
stats.evaluate(target.size());
}这个切入点在所有调用之前添加我的代码Map.put(). 因为我自己正在使用一个映射来存储统计数据,所以我需要排除我自己,以避免令人讨厌的递归。接下来,我为我监视的集合实例获取一个statistics存储对象,以记录访问并评估其使用情况。
这是一种过于简单的方法。我认为在一个单独的线程中定期评估所有统计信息要比在每个请求上都进行同步要好得多。
还有一个有趣的问题:如何识别当前正在检查的集合?为此,我正在使用“identityHashCode”,但我已经知道这可能不是一个明智的想法,因为它可能不是唯一的。
int identityHashCode = System.identityHashCode(targetCollection);收集统计
好的,我已经记录了所有方法的调用计数。我该怎么处理这些数据呢?
public void evaluate(int size) {
if (size >= DANGEROUS_SIZE) {
System.out.printf("\nInformation for Collection %s (id: %d)\n", className, id);
System.out.printf(" * Collection is very long (%d)!\n", size);
if (reads == 0) System.out.printf(" * Collection was never read!\n");
if (deletes == 0) System.out.printf(" * Collection was never reduced!\n");
System.out.printf("Recorded usage for this Collection:\n");
for (String code : interactingCode) {
System.out.printf(" * %s\n", code);
}
}
}对于集合何时表现为“异常”,我并没有确定一个详细的标准。我只是用硬编码的收集长度。对集合进行WeakReference并计算它的控制树是一个很好的主意,但是计算深层大小本身就是一个相当复杂的问题。
除了长度,我认为有两个因素很有趣:
- 这个集合有被读过吗?
- 有什么东西被删除过吗?
两者都是缓存的典型反模式。没有人读取或删除长名单是一个明确的指标,一个问题。所以我才警告你。最后,我打印了所有记录的调用代码,这是一个非常有用的信息!
试运行
Information for Collection java.util.ArrayList (id: 1813612981)
* Collection is very long (5000)!
* Collection was never reduced!
Recorded usage for this Collection:
* de.codecentric.performance.LeakDemo:19
* de.codecentric.performance.LeakDemo:17
* de.codecentric.performance.LeakDemo:18
Information for Collection java.util.ArrayList (id: 1444378545)
* Collection is very long (5000)!
* Collection was never read!
* Collection was never reduced!
Recorded usage for this Collection:
* de.codecentric.performance.LeakDemo:18
Information for Collection java.util.HashMap (id: 515060127)
* Collection is very long (5000)!
* Collection was never read!
* Collection was never reduced!
Recorded usage for this Collection:
* de.codecentric.performance.LeakDemo:19
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at de.codecentric.performance.DummyData.(DummyData.java:5)
at de.codecentric.performance.LeakDemo.runAndLeak(LeakDemo.java:17)
at de.codecentric.performance.DemoRunner.main(DemoRunner.java:12)事实证明有作用!
记录对集合的每次调用都是非常占用内存的。也许我应该这样做,只有当我有迹象表明,这个集合可能会泄漏。但是b使用这些AspectJ切入点,我的代码将始终运行。在一个拥有十万个这样的集合的真实环境中,这肯定不是一个好主意。应该使用动态字节码检测来避免这种情况。当然,长时间的评估比我的快速检查更有意义。
正如我们所看到的,这个想法很容易实现,但是一个生产就绪的解决方案需要大量的思考和聪明的算法。如果你想改进我的分析器。
使用AppDynamics的演示应用程序的内存分析
让我们来看看AppDynamics在专业解决方案中的作用。
10: 43–应用程序服务器重启
启动AppDynamics泄漏检测后,您将无法立即得到结果。它从后台开始分析集合。只有过了一段时间,可能的泄漏才会出现。
11:00–检测到收集

这个java.util.LinkedList由AppDynamics监控。它有56881个条目,这使它确实有趣。但是AppDynamics还没有长时间的信息,所以它没有被标记为“潜在泄漏”。
11:10–集合可能泄漏

时间一天天过去,但集合却不断增多。98850个条目几乎是十分钟前的两倍。内部启发式算法现在将其标记为“潜在泄漏”。
11:17–泄漏越来越严重

概述显示了泄漏的增长。这里还将绘制垃圾收集激活,以可视化使用软引用的效果。
11:30–显示内存泄漏

内容检查向我们展示了集合中的内容。在这种情况下,现在有118990个java.lang.String文件总大小为20MB的对象。
AppDynamics还可以将集合及其内容转储到光盘,以便对内容进行更详细的分析。
11:38–确定根本原因

通过使用访问跟踪会话,AppDynamics可以找出是谁造成了内存泄漏。虽然您可能会使用堆转储来达到这一点,但调用层次结构的列表是很特别的。包含字符串的LinkedList可以在任何地方使用,但是这个泄漏的LinkedList被“newbookmark”业务事务使用。
BookmarkDaoImpl将字符串附加到第50行的列表中。但是,AppDynamics没有看到任何从该列表读取或删除的代码。
所以我们现在得到了修复内存泄漏所需的所有信息:
- 我们可以看到潜在的泄漏结构。
- 我们会自动收到泄漏通知。
- 我们可以看到这些结构的内容。
- 确定负责创建泄漏的业务事务(用例)。
- 记录并显示访问代码。
当然,对于这是内存泄漏还是奇怪的代码,最终的决定仍然取决于开发人员。
总结
可以在运行时发现内存泄漏而不创建堆转储。有关代码的信息对于纠正内存泄漏非常有用。

除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1176.html

 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论