这篇文章主要介绍使用Java的Agent代理技术导致的内存泄露和内存溢出问题,以及如何使用Eclipse的内存分析工具来解决这些问题的。
如果您怀疑Java代理导致应用程序内存不足,或者收到14 OutOfMemoryError错误,那么使用内存分析工具查看来自JVM的堆转储有助于确定前进路径。考虑到一些堆的大小,以及您组织中的安全需求,向我们的团队提供堆转储可能不是一个选择。在本文中,我们将讨论使用eclipsemat来确定内存管理和泄漏检测中的问题区域,因为它与Java代理有关。
内存问题类型
一般来说,Java代理Agent实际上只有3种不同的内存问题。
1) 堆大小太小
这是最简单的内存问题,当用户将其-Xmx值设置得足够低,以至于添加代理只会将它们推到该限制之外时,就会发生这种情况。例如,如果一个用户在-Xmx设置为256MB的情况下运行,并且他们的应用程序被调整为堆使用量为250MB,那么添加代理程序几乎肯定会将他们推到内存之外。
发生这种情况是因为代理有固定大小的内存来运行,而我们没有利用堆外内存来避免这个问题。对于我们的支持团队来说,堆太小不是一个非常常见的问题,但仍然值得注意。
用于分配内存的JVM选项:
-Xms-初始java堆大小-Xmx-最大java堆大小
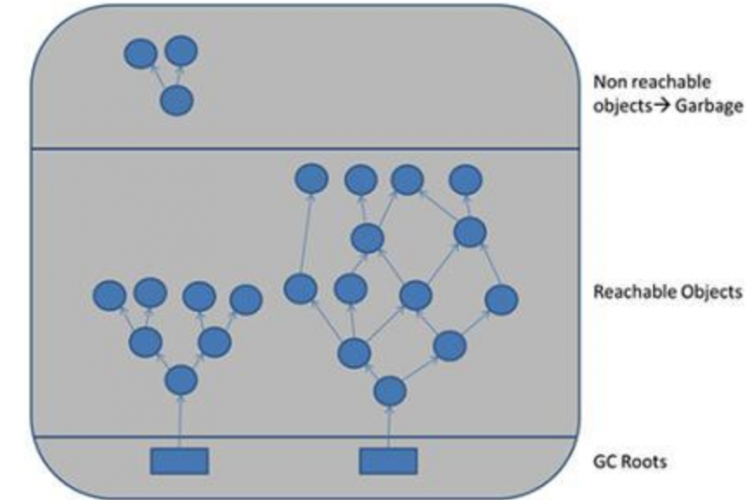
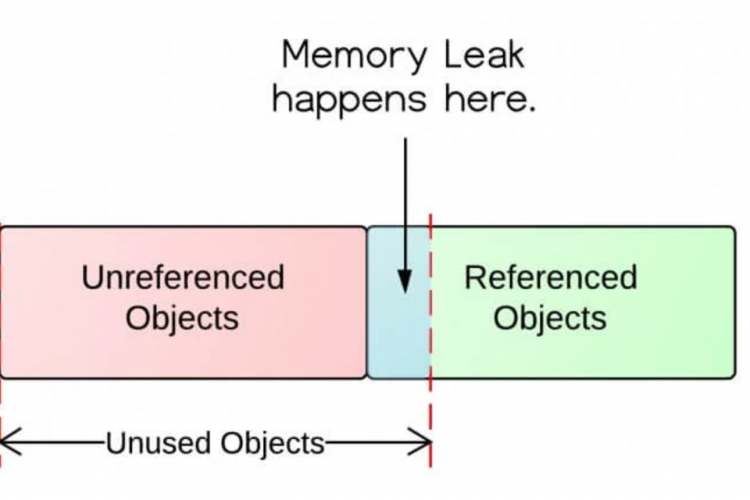
2) 实际内存泄漏(由应用程序代码引起)
这个问题相对来说是不言自明的,只是意味着应用程序总是会发生内存泄漏,而且在连接代理时也会发生。根据我们的判断,这个问题实际上非常罕见,但是可以根据堆转储的内容来确认/拒绝(更多信息见下文)。
3) 真实内存泄漏(在new relic Java代理存在的情况下)
当我们在代理存在的情况下遇到实际内存泄漏时,原因包括(但不限于):
- 类加载器泄漏(防止像Tomcat这样的应用服务器在重新部署时释放内存)
- 存储对从未释放的对象的强引用的检测
- 内部Java代理服务,用于存储对永远不会释放的对象的强引用
- 阻止收集对象的检测(罕见)
需要注意的是,当我们遇到其中一个内存泄漏时,大量用户最终遇到同一个问题是非常常见的。
需要工具和设置
为了分析heap dump,我们将使用Eclipse内存分析器:MAT
你可能需要增加mat可用的堆,以允许加载大型堆转储
- 编辑mat.app/Contents/Eclipse/MemoryAnalyzer.ini文件
- 将
-Xmx1024m更改为-Xmx4096m或类似项(越高越好,取决于您的计算机可用资源)
故障排除步骤
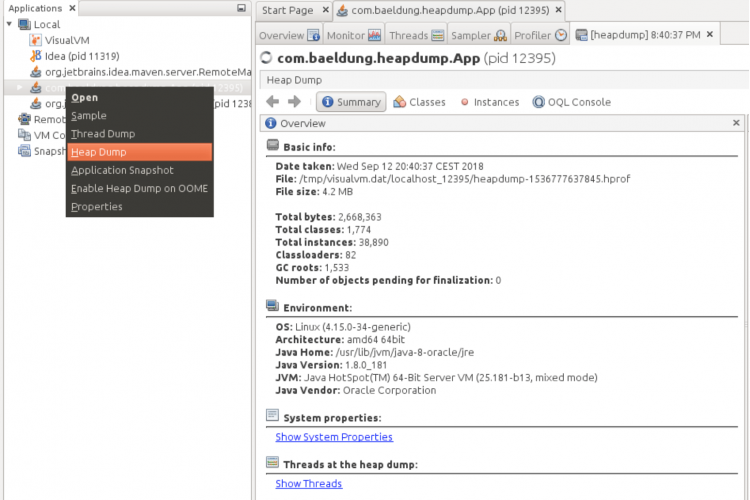
1. 为了解决内存不足的问题,我们必须获取堆转储dump文件。没有其他简单的方法可以在没有堆转储的情况下验证内存问题的原因,堆转储将包含触发转储时堆上所有内容的快照。
有三种方法可以捕获堆转储:
- 通过设置以下JVM属性并允许JVM在触发OutOfMemory错误时自动捕获它:
-XX:+heapDumpOnAutoFmMemoryError - 通过使用以下命令手动触发堆转储:jmap -dump:file=/tmp/app_heapdump.hprof <pid>
- 使用jcmd命令(jdk7之后新增的命令):jcmd <pid> GC.heapdump /tmp/app_heapdump.hprof
注意:只有在堆使用率接近最大值时才运行堆转储,否则它可能不包含堆使用率信息。
2. 现在我们有了一个堆转储dump文件,我们需要在本地下载它并将其加载到Eclipse内存分析器中。堆转储通常以.hprof或.bin结尾,两者都可以通过MAT加载:

3. MAT需要一段时间来解析文件(取决于文件的大小)。完成后,您将看到“入门向导”。选择Leak Suspects Report并单击Finish。这一步不是必需的,但是泄漏嫌疑报告可以帮助您在查找内存泄漏原因时节省一些时间。

4. 一旦转储文件加载完毕,就会显示泄漏嫌疑页面。需要注意的重要事项有:
- 堆的总大小-如果堆的大小远远小于
-Xmx,那么这个转储不太可能有帮助。如果内存泄漏并且转储dump文件在正确的时间被捕获,那么总大小应该非常接近堆的最大大小。 - 每个问题嫌疑的大小-如果我们有一个问题,怀疑占用了堆的50%或更多,很可能我们已经找到内存泄漏的原因。
- 每个问题嫌疑的位置(package)-问题嫌疑的包裹可以告诉我们很多不同的事情。如果问题嫌疑人在
com.newrelic.*那么我们很可能有一个真正的内存泄漏与代理内的事务有关(最常见)。如果可疑问题在用户或应用程序的包中,则需要进行更多的调查以找出泄漏的原因。内存泄漏总是有可能是由于编入应用程序类中的检测错误而发生的。
例如下图:

- 堆的总大小=221.7MB。这相当小,所以除非
-Xmx设置为256MB,否则不一定表示内存泄漏。 - 怀疑的问题只占整个堆的25%,因此在本例中这些问题不太可能是重要的。
- 怀疑的问题之一是类加载器这一事实很有趣,这可能表明检测或代理有问题,因为我们确实广泛地使用了类加载器。但请注意,这两个都在
com.newrelic.*前缀所以在这一点上它不是一个银弹。
故障排除步骤示例1:
在最初查看堆转储时,您需要从概述页查看泄漏嫌疑:

这将显示哪些项保存了最多的内存。在本例中,您将看到实际上只有一项,new relic java Agent代理的事务服务(com.newrelic.agent(事务服务):

如果你点击底部的Details按钮,你会看到一个页面,其中显示了保存所有内存的对象的详细信息。在本例中,我们看到许多由updateQueue持有的ConcurrentHashMap节点:

要深入到updateQueue,请单击updateQueue右侧TransactionService对象的链接,然后选择"List objects and with outgoing references":

您可以将树向下展开到updateQueue,然后进一步扩展到存储在其中的事务对象。您通过查找并选择priorityTransactionName来查找这些事务的名称—它的字段将显示在左侧面板上。我们要特别查找事务的partialName:

我们现在可以看到,在这个示例中/SpringController/coupon/discountList/{placeId}(GET)事务似乎是问题的根源。
既然我们知道哪些事务被事务服务保存在内存中,我们就可以开始调查了。
- 我们对那个端点了解多少?
- 是否有任何自定义仪器正在使用中?
- 完成事务需要多长时间(长时间运行的事务)?
示例故障排除步骤2:
如前所述,您需要从概述页查看泄漏嫌疑:

您将看到有一个条目,new relic Java Agent代理的事务服务(com.newrelic.agent.TransactionService)。如果你点击底部的Details按钮,你会看到一个页面,其中显示了保存所有内存的对象的详细信息。在本例中,我们再次看到许多ConcurrentHashMap节点由updateQueue持有:

要深入到updateQueue,请单击updateQueue右侧TransactionService对象的链接,然后选择"List objects and with outgoing references":

将树向下展开到updateQueue,然后展开到其中存储的事务对象。通过查找并选择priorityTransactionName,然后选择事务的partialName来查找这些事务的名称:

我们现在可以看到,在这个例子中/Custom/API网关调度事务似乎是问题的根源,我们可以开始调查。
重要提示:
看到com.newrelic.agent.instrumentation.context.InstrumentationContextManager在支配树顶部附近并不表示我们的代理有内存泄漏。这个类占用10-25MB的堆空间并不少见,因为我们使用它来缓存重要的相关信息。

除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1118.html
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论