
如何在JAVA中构建区块链?
区块链炒作继续困扰着技术世界。与此同时,许多银行和软件公司也意识到了这一点,并试图将相应的产品投放市场。然而,任何对区块链技术有更深理解和了解的人都会意识到它的缺点。尽管被认为是一种破坏性技术,但它可能更适合于特殊应用,而不是普通大众。 与其他IT技术并列,区块链是一个相当难以接近的技术。这部分是由于复杂的底层算法,但也因为区块链中包含了许多不同的概念和技术。尽管如此,这个话题还是因为与普遍存在的
区块链炒作继续困扰着技术世界。与此同时,许多银行和软件公司也意识到了这一点,并试图将相应的产品投放市场。然而,任何对区块链技术有更深理解和了解的人都会意识到它的缺点。尽管被认为是一种破坏性技术,但它可能更适合于特殊应用,而不是普通大众。 与其他IT技术并列,区块链是一个相当难以接近的技术。这部分是由于复杂的底层算法,但也因为区块链中包含了许多不同的概念和技术。尽管如此,这个话题还是因为与普遍存在的

创造一个新产品就是风险。选择正确的体系结构是迈向成功的关键一步。如果您正在考虑单体、service-oriented、微服务和serverless无服务器体系结构,这篇博文将帮助您做出正确的选择。 单体结构 巨石是一个古老的词,指的是一块巨大的石头。尽管这个术语在今天被广泛使用,但图像在各个领域都保持不变。在软件工程中,单片模式是指单个不可分割的单元。单片软件的概念在于将应用程序的不同组件组合到单

虽然Java初学者很快就学会了键入public static void main来运行他们的应用程序,但即使是经验丰富的开发人员也常常不知道JVM对Java进程的另外两个入口点的支持:premain和agentmain方法。这两种方法都允许所谓的Java代理在驻留在自己的jar文件中时对现有Java程序作出贡献,即使主应用程序没有显式链接。这样,就可以完全独立于承载Java代理的应用程序开发、发布

微服务是构建应用程序的体系结构方法。作为一个架构框架,微服务是分布式的、松散耦合的,因此一个团队的更改不会破坏整个应用程序。使用微服务的好处是,开发团队能够快速构建应用程序的新组件,以满足不断变化的业务需求 一种构建应用程序的方法,针对DevOps和CI/CD进行了优化 将微服务体系结构与更传统的单一方法区分开来的是它如何将应用程序分解为其核心功能。每个功能都称为一个服务,可以独立构建和部署,这意

在Spring5正式发布之后,值得一看它的当前版本。此外,我们将尝试将我们的反应式微服务放在Spring云生态系统中,该生态系统包含诸如Eureka的服务发现、Spring Cloud Commons@LoadBalanced的负载平衡以及使用Spring Cloud gateway的API gateway(也基于WebFlux和Netty)等元素。我们还将通过SpringDatareactive

Java代理Agents通过提供使我们能够侵入JVM中正在运行的Java程序的服务,在最底层工作。Java的这一强大但不可思议的部分具有在错误操作时使JVM崩溃的能力。本文简要介绍了这个概念,并介绍了它的工作原理。 表示Java Agents的类显然只不过是Java API库中的任何其他类。但是,让它们与众不同的是,它们遵循某种约定,这种约定使Java代码能够拦截JVM中运行的另一个应用程序。其目

垃圾收集:有很多技术定义,但用外行术语来说,它只是从内存中收集未引用或未使用(垃圾)对象并有效利用应用程序可用内存的一种自动化方法。 从这里开始,让我们节省一些空间,并使用“GC”作为垃圾收集的缩写。 GC的发展 在java之前,用C或C++,我们必须使用MalCube()/RealCube()/CalOrthAube(/For)/free()来显式分配或分配内存。因为我们必须显式地管理内存分配,

数年来,DataStax一直关注信息传递。一个重要的动机是基于微服务的体系结构越来越流行。简单地说,微服务架构使用消息总线来分离服务之间的通信,并简化重播、错误处理和负载峰值。 通过Cassandra和Astra,开发人员和架构师拥有一个数据库生态系统 1. 基于开源 2. 非常适合混合和多云部署 3. 可在云本地消费定价服务中使用 目前没有满足这些要求的消息传递解决方案,因此我们正在构建一个。

大家好。在本博客中,我们将看到如何使用GraalVm实现多语言。这方面的先决条件是: 对GraalVm的理解。 了解GraalVm提供的功能。 GraalVm的本地设置。 一点java和python(可选)。 让我们开始吧。 什么是GraalVm? GraalVm是Oracle的一个开源项目,其目标是针对JVM,以便多个语言可以共存于同一个应用程序中。GraalVm不是JVM,而是一个UVM(通用

Java8于2014年3月发布,并引入了lambda表达式作为其旗舰功能。您可能已经在代码库中使用它们来编写更简洁、更灵活的代码。例如,您可以将lambda表达式与新的Streams API结合起来,以表达丰富的数据处理查询: int total = invoices.stream() .filter(inv -> inv.getMonth() == Month.JULY) .mapToIn

区块链是数字加密货币比特币的核心技术。区块链是一个分布式数据库,包含参与方之间已执行和共享的所有交易或数字事件的记录。每一笔交易都经过系统大多数参与者的验证。它包含每笔交易的每一条记录。比特币是最流行的加密货币,也是区块链的一个例子。区块链技术最早出现在2008年,当时有一个人或一群叫“Satoshi Nakamoto”的人发表了一篇关于“比特币:点对点电子现金系统”的白皮书。区块链技术将交易记录
在计算中,服务是指执行重复、冗余任务的单个或集体软件单元。在云计算时代,应用程序由一组服务组成,这些服务共同执行各种功能,以支持应用程序的整体功能。 在本文中,我们将探讨微服务体系结构(MSA)和面向服务体系结构(SOA)作为两种常见的基于服务的体系结构,它们如何依赖服务作为主要组件,以及它们在服务特性方面的差异。 我们来看看。 什么是面向服务的体系结构(SOA)? 面向服务的体系结构遵循多个自包
Java平台的一个经常被忽略的特性是在JVM的解释器或即时(JIT)编译器执行程序之前修改程序字节码的能力。虽然此功能由工具使用,例如进行对象关系映射的探查器和库,但应用程序开发人员很少使用它。这代表了未开发的潜力,因为在运行时生成代码允许轻松实现跨领域问题,如日志记录或安全性,有时以模拟或编写性能数据收集代理的形式更改第三方库的行为。 目前有三个主要的库用于生成字节码: ASM cglib Ja

微服务架构(简称micro services)是一种独特的软件系统开发方法,它试图专注于构建具有定义良好的接口和操作的单一功能模块。近年来,随着企业希望变得更加敏捷,并朝着DevOps和持续测试的方向发展,这一趋势变得越来越流行。 微服务对敏捷和DevOps团队有很多好处——正如Martin Fowler指出的那样,Netflix、eBay、亚马逊、Twitter、PayPal和其他技术明星都已经

在本文中,我们将学习如何配置Vault PKI引擎并将其与Spring WebFlux集成。使用Vault PKI,您可以轻松生成由CA签名的X.509证书。然后,您的应用程序可以通过REST API获得证书。它的TTL相对较短。每个应用程序实例都是唯一的。此外,我们还可以使用SpringVault模板简化与Vault API的集成。 让我们再多说一点关于安全库的事。它允许您使用UI、CLI或HT

为什么我需要设置JAVA_HOME? 许多基于Java的程序,如Tomcat,需要将Java_HOME设置为环境变量才能正常工作。请注意,JAVA_HOME应该指向JDK目录,而不是JRE目录。设置环境变量的目的是让程序知道可以在哪个目录中找到像javac这样的可执行文件。 打开高级系统设置 在Windows 10中,按Windows键+Pause暂停键,将打开系统设置窗口。转到“更改设置”并选择

假设您有一个在生产环境中运行的应用程序。每隔一段时间,它就会进入中断状态,错误很难重现,您需要从应用程序中获得更多信息。 那么你想知道解决方案吗? 您可以做的是动态地将一些代码集附加到应用程序中,并仔细地重写它,以便代码转储您可以记录的其他信息,或者您可以将应用程序阶段转储到文本文件中。Java为我们提供了使用Java Agent实现这一点的工具。 你有没有想过我们的Java代码是如何在IDE中进
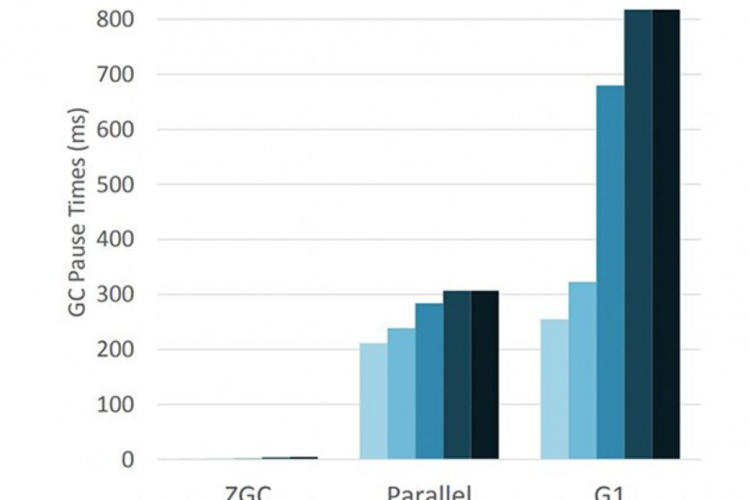
ZGC、Shenandoah和对G1的改进使开发人员比以往任何时候都更接近无停顿Java。 在过去的六个月里,JDK的垃圾收集器(GC)出现了一些最令人兴奋的发展。本文介绍了一系列不同的改进,其中许多最早出现在JDK 12中,并在JDK 13中继续介绍。首先,我们将介绍Shenandoah,一种低延迟GC,它主要与应用程序同时运行。我们还将介绍作为JDK 12的一部分发布的ZGC(Java11中引

Serverless是一种cloud-native云本地开发模型,允许开发人员构建和运行应用程序,而无需管理服务器。 serverless中仍然有服务器,但它们被抽象出应用程序开发。云提供商处理服务器基础设施的供应、维护和扩展等日常工作。开发人员可以简单地将代码打包到容器中进行部署。 一旦部署,无服务器应用程序将响应需求,并根据需要自动上下扩展。公共云提供商提供的无服务器服务通常通过事件驱动的执行

在本文中,我们将介绍ApachePulsar的设计,以便更好地设计故障场景。这篇文章不是为那些想了解如何使用ApachePulsar的人写的,而是为那些想了解它是如何工作的人写的。我一直在努力以一种简单易懂的方式对其架构进行清晰的概述。 主要的声明包括: 保证不会丢失消息(如果采用了建议的配置,并且您的整个数据中心不会被烧毁) 强排序保证 可预测的读写延迟 Apache Pulsar选择一致性而不
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

更多干货请关注公众号【Java老K】

录制线上真实流量在测试环境进行回放,对比差异
特点:
无代码侵入的数据采集和Mock,支持Spring、Dubbo、Redis、Mybatis等开源框架的录制和回放;
支持各种复杂业务场景的验证:多线程并发、异步回调、写操作等;
欢迎扫码进QQ群交流