John Miiler 是ebay团队的高级后端工程师,负责各种项目,包括结账和支付系统。作为公司摆脱单一业务的努力的一部分,他的团队正试图将业务逻辑一块一块地提取到单独的微服务中。他分享了他的团队如何解决在提取图像处理微服务时遇到的内存使用问题。
最近提取的microservice是一种图像处理服务,它对图像进行大小调整、裁剪、重新编码和执行其他处理操作。这个服务是一个在Docker容器中使用springboot构建的Java应用程序,并部署到AWS托管的Kubernetes集群中。在实现该服务时,我们偶然发现了一个巨大的问题:该服务存在内存使用问题。本文将讨论我们识别和解决这些问题的方法。我将从对一般记忆问题的简要介绍开始,然后深入研究解决这个问题的过程。
我以为是内存泄露。但是在使用内存分析器(MAT)时,当我比较一个快照和另一个快照的内存使用情况时,我的“惊喜”时刻到来了,我意识到问题在于springboot产生的线程数
内存问题概述
有许多类型的错误直接或间接地影响应用程序。本文主要讨论其中的两个问题:OOM(内存不足)错误和内存泄漏。调查这类错误可能是一项艰巨的任务,我们将详细介绍在我们开发的服务中修复此类错误所采取的步骤。
1. 了解OOM错误并确定其原因
OOM错误代表第一类内存问题。它可以归结为一个试图在堆上分配内存的应用程序。但是,由于各种原因,操作系统或虚拟机(对于JVM应用程序)无法满足该请求,因此,应用程序的进程会立即停止。
使识别和修复变得非常困难的是,它可以在任何时候从代码中的任何位置发生。因此,仅仅查看一些日志来确定触发它的代码行通常是不够的。一些最常见的原因是:
- 应用程序需要比操作系统提供更多的内存。有时这可以通过简单地添加更多的RAM来解决。但是,在一台机器上可以添加多少RAM是有限制的,所以应该尽可能避免内存的过度使用。
- Java应用程序使用默认的JVM内存限制,这通常相当保守。随着应用程序规模的增长和更多特性的添加,它最终会超过这个限制,并将被JVM杀死。
- 内存泄漏对于长时间运行的进程来说,最终将导致没有足够的资源。
有各种各样的开源和开源工具,用于检查进程的内存使用情况以及它是如何演变的。我们将在后面的部分讨论这些工具。
2. 了解内存泄漏
首先让我们了解什么是内存泄漏。内存泄漏是一种资源泄漏类型,当程序释放丢弃的内存时发生故障,导致性能受损或失败。当一个对象存储在内存中,但运行的代码无法访问时,也可能发生这种情况。
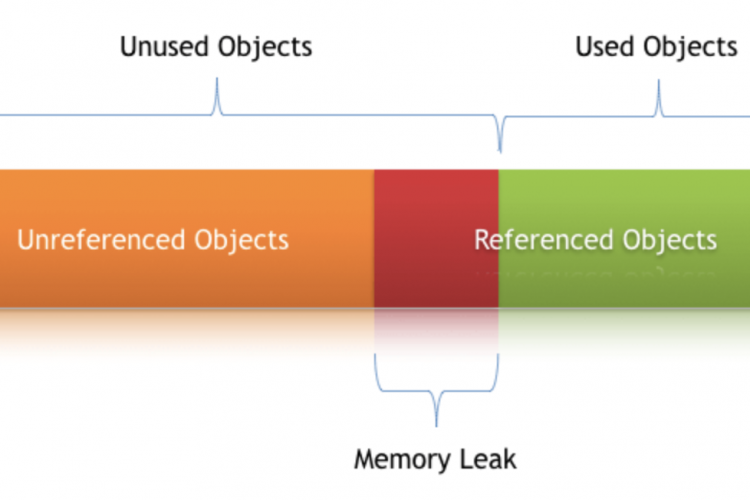
这听起来很抽象,但在现实生活中,内存泄漏究竟是什么样子呢?让我们看一个用垃圾回收(GC)语言编写的应用程序内存泄漏的典型示例。

该图显示了旧的Gen内存(老年代对象)的内存模式。绿线显示分配的内存,紫色线显示GC对Old Gen memory执行扫描阶段后的实际内存使用量,垂直红线显示GC步骤前后内存使用量的差异。
正如您在本例中所看到的,每个垃圾收集步骤都会略微减少内存使用量,但总体而言,分配的空间会随着时间的推移而增长。此模式表示并非所有分配的内存都可以释放。
3. 内存泄漏的主要原因
内存泄漏有多种原因。我们将在这里讨论最常见的。第一个也是最容易被忽视的原因是静态变量的滥用。在Java应用程序中,只要所有者类加载到Java虚拟机(JVM)中,静态字段就存在于内存中。如果类本身是静态的,那么将在整个程序执行过程中加载该类,因此类和静态字段都不会被垃圾回收。
这个问题的实际解决办法出人意料地简单。我们选择将默认线程池从200个线程覆盖到16个线程。
未关闭的流和连接是内存泄漏的另一个原因。一般来说,操作系统只允许有限数量的打开的文件流,因此,如果应用程序忘记关闭这些文件流,在一段时间后,最终将无法打开新文件。
同样,允许的开放连接的数量也受到限制。如果一个人连接到一个数据库但没有关闭它,在打开一定数量的这样的连接之后,它将达到全局限制。在此之后,应用程序将无法再与数据库通信,因为它无法打开新的连接。
最后,内存泄漏的最后一个主要原因是未释放的本机对象。如果本机库本身有漏洞,那么使用本机库JNI的Java应用程序很容易遇到内存泄漏。这些类型的泄漏通常是最难调试的,因为大多数时候,您不一定拥有本机库的代码,并且通常将其用作黑盒。
关于本机库内存泄漏的另一个方面是,JVM垃圾收集器甚至不知道本机库分配的堆内存。因此,人们只能使用其他工具来解决此类泄漏问题。
好吧,理论够了。让我们看一个真实的场景:
4. 案例研究-修复图像处理服务中的OOM问题
现状
如简介部分所述,我们一直致力于图像处理服务。以下是开发初始阶段内存使用模式的外观:

在这张图中,Y轴上的数字表示内存的GiBs。红线表示JVM可用于堆内存(1GiB)的绝对最大值。深灰色线表示一段时间内的平均实际堆使用量,灰色虚线表示随时间推移的最小和最大实际堆使用量。开头和结尾处的峰值表示应用程序被重新部署的时间,因此在本例中可以忽略它们。
该图显示了一个明显的趋势,因为它从大约需要的300MB堆开始,然后在短短几天内增长到超过800MiB,而在Docker容器中运行的应用程序将由于OOM而被杀死。

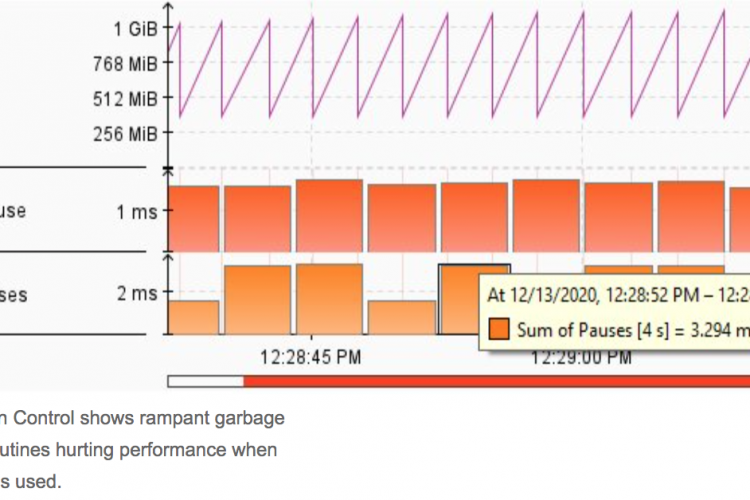
为了更好地说明这种情况,让我们也看看在同一时间段内应用程序的其他指标。
看看这个图,内存泄漏的唯一迹象是堆使用率和GC旧gen大小随着时间的推移而增长。当堆空间使用量达到1GiB时,运行Docker容器的Kubernetes pod就要被杀死了。每一个其他指标看起来都很稳定:线程数一直保持在略低于40的水平,加载的类的数量也很稳定,非堆的使用也很稳定。
这些图表中唯一缺少的变量是垃圾收集时间。它与堆上分配的内存成比例增加。这意味着响应时间越来越慢,应用程序运行的时间越长。
5. 故障排除
我们试图解决这个问题的第一步是确保所有的流和连接都关闭了。有些角落的案子我们一开始没有涉及。然而,一切都没有改变。我们观察到的行为和以前完全一样。这意味着我们必须更深入地挖掘。
下一步是查看本机内存的使用情况,并确保最终释放所有分配的内存。我们用来为服务做重载的OpenCV库不是java库,而是本地C++库。它提供了一个可以在应用程序中使用的Java本机接口。
因为我们知道OpenCV有可能泄漏Java本机内存,所以我们确保所有OpenCV Mat对象都被释放,并在返回响应之前显式地调用GC。仍然没有明确的泄漏指示器,内存使用模式也没有任何变化。
到目前为止还没有明确的指示,是时候用专用工具进一步分析内存使用情况了。首先,我们研究了内存分析器工具中的内存转储。
第一个转储是在应用程序启动后生成的,只有几个请求。第二个转储是在应用程序达到1GiB堆使用率之前生成的。我们分析了在这两种情况下分配的内容和可能引起问题的内容。乍一看没有什么不寻常的事。
然后我们决定比较堆上最需要的内存。令我们惊讶的是,堆上存储了相当多的请求和响应对象。这是“bingo”时刻。

深入研究这个内存转储,我们发现堆上存储了44个响应对象,比初始转储中的响应对象要高得多。这44个响应对象实际上都存储了自己的launchDurlClassLoader,因为它位于一个单独的线程中。每个对象的保留内存大小都超过3MiB。

我们允许应用程序为我们的用例使用很多的线程。默认情况下,springboot应用程序使用大小为200的线程池来处理web请求。这对于我们的服务来说太大了,因为每个请求/响应都需要几MB的内存来保存原始/调整大小的图像。因为线程只是按需创建的,所以应用程序开始时的堆使用量很小,但随着每个新请求的增加,使用量越来越高。
这个问题的实际解决办法出人意料地简单。我们选择将默认线程池从200个线程减少到16个线程。这就彻底解决了我们的内存问题。现在堆终于稳定了,因此GC也更快了。

6. 识别内存问题的工具
在调查和排除此问题的过程中,我们使用了几个被证明是必不可少的工具:
Datadog
我们手头上的第一个工具是针对JVM度量的DataDog APM仪表板,它非常容易使用,允许我们获得上面的图形和仪表板。
Jemalloc和jeprof
我们用来分析堆使用率和本机内存使用情况的另一个工具是jemalloc库的使用情况来分析对malloc的调用。为了能够使用jemalloc,需要使用apt get install libjemalloc dev进行安装,然后在运行时将其注入Java应用程序:
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libjemalloc.so MALLOC_CONF=prof:true,lg_prof_interval:30,lg_prof_sample:17 java [arguments omitted for simplicity ...] -jar imageprocessing.jar总而言之,我以为是内存泄漏。但是最后发现问题出在springboot生成的线程数上。

除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/982.html


 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论