当我第一次听说DDD(领域驱动设计,当然不是期限驱动设计)时,我还是惠普(Hewlett-Packard)位于马来西亚Cyberjaya的开发中心的高级Java开发人员。我对这个话题不太感兴趣,因为在那段时间里很难找到好的资源。有人让我找到埃里克·埃文的书(“蓝皮书”),我得到了这本书,并将它添加到我的PDF收藏中。
在这段时间里,DDD是一项全新的技术(尤其是在印度尼西亚),因此只有少数公司成功地实施了这项新技术。不知何故,我发现许多DDD资源太难被大多数读者掌握(即,它们太抽象,缺乏好的示例)。因此,我打算拿起这个非常棒的主题,以一个系列的形式编写它,并配备一个应用程序示例,以便一步一步地遵循。
在引言的第一部分中,我想从以下几个基本概念开始:
- DDD是关于什么的?
- 我们如何开始?
- DDD中应该避免什么?
让我们开始吧!
DDD是关于什么的?
在本节开始时,我更愿意从DDD的一个社区dddcommunity.org中获取定义,该社区将DDD描述为一种通过将实现与核心业务概念的不断发展的模型深度连接来开发满足复杂需求的软件的方法。
正如定义所暗示的,如果您正在构建业务流程(业务域)复杂的软件,那么DDD非常适合您。因此,并非所有软件都适用于DDD(例如,CRUD应用程序不适用于DDD,因为它们不是很复杂)。
团队合作在DDD中非常重要,因为您需要与用户/客户保持联系(也称为领域专家)。此外,你为他们而不是为你构建软件(你的观点是正确的)。正如有人所说:“软件可能会以两种方式失败,一种是你构建了错误的东西,另一种是你构建了错误的东西。”在这种情况下,你必须确保你理解你将要构建的业务。这就是DDD的意义所在。
总之,DDD可以被描述为一种开发软件的技术,其重点是技术专家和领域专家之间的协作。因此,我们必须关注领域专家,而不是技术人员的细节。
我们如何开始?
首先,正如前面提到的,重要的一点是与业务/领域专家保持联系。在与领域专家进行讨论时,我将重述几点我们可以用作指导的要点:
- 了解问题域,即您正在处理的软件试图解决的特定问题。查看当前业务流程的总体情况。
- 将域拆分为子域。
- 与领域专家一次关注一个子领域,并始终使用通用语言定义术语。
- 在子域之间创建有界上下文。同样,无处不在的语言应该始终在整个有界上下文中使用,从对话到代码,在图表中,在白板上,在设计文档中,在团队讨论中,等等。重点是在任何地方使用有界上下文。
- 理想情况下,每个有界上下文将有不同的团队、代码库和数据库。
- 因为每个人都在为自己的有界上下文工作,所以他们可以自由地更改上下文中的任何内容。
- 对于所有在有界上下文(我们称之为共享内核)之间共享的横切关注点,所有团队在每个有界上下文中都应该知道并同意任何更改。
- 始终关注域的行为,而不是域的状态(支持丰富的模型而不是贫乏的模型)。
总之,在整个团队中始终使用通用语言(即相同的术语),通过定义边界将域划分为更小的子域,并提供隔离(即有界上下文),并考虑有界上下文中的子域如何使用接口/特制的软件契约相互通信。
DDD中应该避免什么?
另一方面,在DDD实现过程中,我们需要小心某些在软件开发人员中太常见的实践。这些是:
1) 在对问题域建模时使用以数据为中心的视图
通常,数据模型是架构师/开发人员开始设计的第一件事。他们总是认为数据是最重要的,因为数据是我们需要报告的全部内容。如果你从DDD开始,你必须改变这种心态。数据本身毫无意义。只有逻辑赋予数据意义,相同的数据在不同的上下文中可能具有不同的意义。因此,我们必须从上下文和逻辑而不是数据开始。
2) 关注实体、价值对象、服务、工厂和存储库等实现细节,而不是核心概念
实体、值对象、存储库等等都没有意义,直到我们定义了无处不在的语言、有界的上下文和接口/精心编制的软件契约。如果我们尽早开始像实体一样的实现细节,那么结果很有可能是一个贫乏的领域,被分散在各处的大量服务和业务逻辑所包围。
3) 在实现应用程序时使用通用和特定于开发人员的术语和概念
我们不应该使用诸如保存、更新、删除、处理、管理等概念。这些概念太过技术化——没有具体意义的抽象概念。相反,我们必须专注于业务概念。上述概念(即保存、更新等)与业务概念无关。为了理解这一点,我鼓励自己总是想象客户在没有计算机的情况下运行他的差事/业务(手动执行特定任务)。因此,始终从业务/领域专家的角度思考,并给出一个清晰的上下文。避免使用在不同的非特定上下文中可能导致不同含义的通用术语。
4) 高估DB事务,而不是关注业务流程或事务
DDD中的事务比业务中的事务更重要。DB事务是ACID、强一致性和短期运行的,而业务事务则不是。事实上,在现实生活中,我们不知道数据库事务,我们只知道业务事务。例如,想象一下,当你坐在一家餐馆里点一些食物或饮料时。在订单事务中,无论是否实现,都会有一个包含一些异步任务的流程,其中可能有许多不一致的状态变化;到最后,所有国家都将保持一致(最终保持一致)。这个黑盒过程有效,可扩展,并且被所有人广泛接受。因此,对于DDD,永远不要考虑DB事务。相反,要始终考虑现实世界中的过程,例如行动(行为)及其可能的结果,或者在发生故障时如何补偿行动。
现在你不必理解上面提到的所有要点。我知道大多数应用程序开发人员都不太熟悉这些概念的习惯用法和特性。
第一件事:您必须了解以下DDD构建块:
- 实体
- 价值对象
- 聚合根
- 存储库
- 工厂
- 服务
系好安全带!我们现在正在研究这些细节。
实体
实体是具有标识(ID)且可能可变的普通对象。每个实体都由ID而不是属性唯一标识;因此,如果两个实体具有相同的ID,即使它们具有不同的属性,也可以认为它们是相等的(标识符相等)。这意味着实体的状态可以随时更改,但只要两个实体具有相同的ID,则无论它们具有什么属性,都将认为它们是相等的。
价值对象
值对象是不可变的。他们没有我们在实体中找到的身份(ID)。如果两个值对象具有相同的类型和相同的属性(应用于其所有属性),则可以认为它们相等。
消息传递之类的东西通常会被使用,事实上,这在洋葱架构中的API层中特别有用,可以公开域概念,而不必公开不变的方面。
价值对象的一些好处:
价值对象的复合可以吞噬大量的计算复杂性。
实体可以从逻辑复杂性中解放出来。
提高可扩展性,特别是在正确使用时,针对可测试性和并发性问题。
聚合根
聚合根是与其他实体绑定在一起的实体。此外,aggregate root实际上是aggregate的一部分(关联对象的集合/集群,为了数据更改的目的被视为单个单元)。因此,每个聚合实际上由聚合根和边界组成。例如,可以将SalesOrderDomain中Order和OrderLineItem之间的关系视为聚合,其中Order充当聚合根,而OrderLineItem是SalesOrder边界中Order的子级。
聚合根的关键特性之一是不允许外部对象持有对聚合根子实体的引用。因此,如果您需要访问一个聚合根子实体(AKA aggregate),那么您必须通过聚合根(即,您不能直接访问子实体)。
另一件事是域中的所有操作都应该尽可能通过聚合根。工厂、存储库和服务是其中的一些例外,但只要有可能,如果您可以创建或要求操作通过聚合根,那就更好了。
存储库Repositories
存储库主要用于处理存储。它们实际上是DDD中最重要的概念之一,因为它们抽象出了许多存储关注点(即某种形式/存储机制)。
存储库实现可以是基于文件的存储,或者数据库(基于SQL-/NoSQL),或者与存储机制相关的任何其他东西,例如缓存。这些因素的任何组合也是可能的。
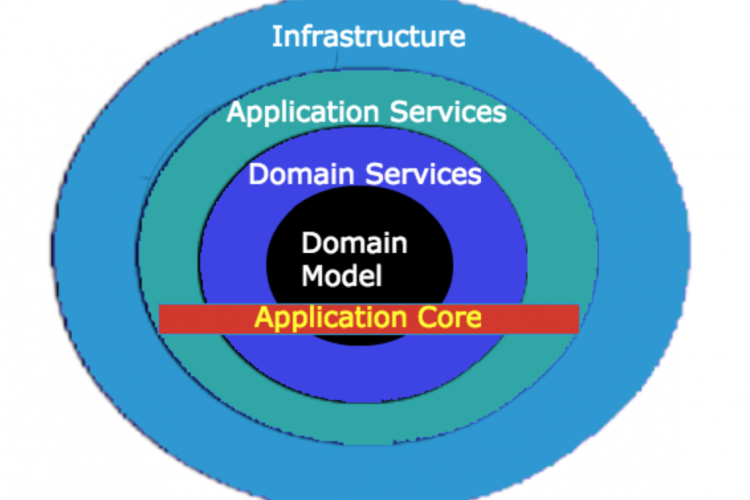
存储库不应与数据存储混淆。存储库作业是存储聚合根。在这下面,存储库实现可能实际上必须与多个不同的存储位置进行通信,以便构建聚合。因此,可以从RESTAPI以及数据库或文件中提取单个聚合根。您可以将它们封装在称为数据存储的东西中,但存储库是所有这些单独数据存储之上的抽象的另一层。通常,我将存储库实现为洋葱架构中的域/域服务层中的一个接口,然后将在基础架构层中定义存储库接口的实现逻辑。
工厂
工厂用于对对象构造进行抽象(参见GOF中的工厂设计模式)。
工厂还可能返回聚合根或实体,或者可能返回值对象。
通常情况下,当您需要聚合根目录的工厂方法时,它将被滚动到存储库中。因此,您的存储库可能有一个finder create方法。
通常,工厂也作为域/域服务层中的接口实现,实现逻辑将在基础架构层中定义。
服务
服务基本上是为不完全适合聚合根的操作提供一个主目录。例如,当您有一个操作并且不知道它进入哪个聚合根时,可能它在多个聚合根上操作,或者可能它不属于任何现有的聚合根。然后,您可以将逻辑放入服务中。但是,不要急于将所有东西都投入到服务中。首先也是最重要的是,最好仔细分析操作是否适合现有聚合根之一。如果您找不到聚合根,那么接下来最好问问自己是否遗漏了一个聚合根,或者在将操作放入服务之前,您还没有考虑将一些域概念引入到您的域中。
其他重要的事情
我经常发现许多开发人员交替使用术语VO(值对象)和DTO(数据传输对象)。他们认为两者完全相同。这对我来说很烦人。我想在此澄清,两者所指的是不同的事物。
VO和DTO是POJO/POCO的子集。实体也是POJO/POCO的子集。
POJO和POCO可以互换使用。两者都是指类似的事情。两者都只是域对象,主要表示业务应用程序中的域/业务对象。
术语POJO(普通旧Java对象)由Martin Fowler提出,在Java社区非常流行,而POCO(普通旧CLR对象/普通旧类对象)在dotNet中被广泛使用。
如前所述,DTO、VO和entity只是POJO/POCO的子集。但是,它们实际上是不同的东西,如下所述:
DTO只是一个愚蠢的数据容器(只保存没有任何逻辑的数据)。因此,它通常是贫血的(只包含属性和getter/setter)。DTO是绝对不变的。通常,我们使用DTO在单个应用程序的层和层之间传输对象,或者在应用程序到应用程序或JVM到JVM之间传输对象(在网络之间最有用的是减少多个网络调用)。
VO也是不可变的,但与DTO不同的是,VO还包含逻辑。
原文地址:https://dzone.com/articles/ddd-part-i-introduction
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/2192.html
 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论