在Java中,所有对象都存储在堆中。它们由新的操作符分配,当JVM确定没有程序线程可以访问它们时,它们将被丢弃。大多数时候,这种情况都是悄无声息地发生的,程序员也不会再想一想。然后,通常在截止日期前一天左右,程序就会终止。
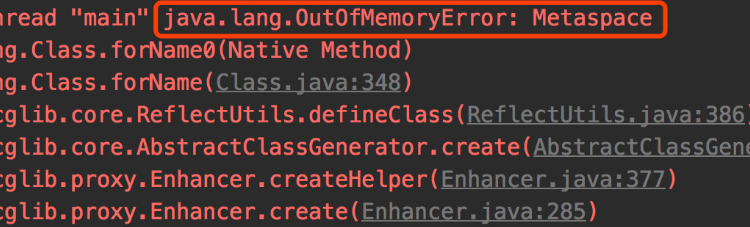
Exception in thread "main" java.lang.OutOfMemoryError: Java heap spaceOutOfMemoryError是一个令人沮丧的例外。这通常意味着你做错了事情:要么抓住对象太久,要么一次处理太多数据。有时,它表示您无法控制的问题,例如缓存字符串的第三方库,或者部署后不清理的应用程序服务器。有时,它与堆上的对象无关。
本文将研究OutOfMemoryError的不同原因,以及您可以采取的措施。这里以Oracle的HotSpotVM为准,这是我使用的一个JVM。然而,大部分内容适用于任何JVM实现。它是根据网上的文献和我自己的经验写成的。我不研究JVM的内部结构,所以不能站在权威的立场上说话。但我已经面对并解决了很多内存问题。
垃圾收集概述
我已经在别处详细描述了垃圾收集过程。总而言之,mark-sweep收集器从“GC ROOT 垃圾收集根”开始,遍历整个对象图,标记它所触及的每个对象。未被触及的对象是垃圾,将被收集。
Java的垃圾收集方法意味着,内存耗尽的唯一方法是不断地向图中添加对象,但不删除它们。通常,这是因为您将对象添加到从静态变量引用的集合(通常是映射)中。或者,由ThreadLocal或长寿命线程的Runnable保存的集合的情况较少。
这与C和C++程序中的内存泄漏非常不同。在这些语言中,当方法调用malloc()或new,然后返回而不调用相应的free()或delete时,就会发生泄漏。这些是真正的泄漏:如果不使用工具将每个分配与其相应的释放相匹配,您将永远无法恢复内存。
在Java中,“泄漏”的内存只是放错了地方。就JVM而言,它已经被考虑在内了。问题是你,程序员,不知道在哪里。幸运的是,有办法找到它。
在深入研究这些技术之前,关于垃圾收集器还有最后一件事要知道:它将尽最大努力在JVM抛出OutOfMemoryError之前释放内存。也就是说垃圾回收System.gc()解决不了你的问题。你得找到漏洞自己堵住。
设置堆大小
正如学究们喜欢指出的那样,Java语言规范并没有提到垃圾收集:您可以实现一个永远不会释放内存的JVM(并不是说它会非常有用)。Java虚拟机规范注意到堆是由垃圾收集器管理的,但是显式地保留了实现细节。关于垃圾收集的唯一保证是我上面提到的:收集器(如果存在)将在JVM抛出OutOfMemoryError之前运行。
实际上,JVM使用一个固定大小的堆,允许在最小和最大界限之间根据需要增长。如果不指定这些边界,“client客户机”JVM的默认值最小为2Mb,最大为64Mb;“server服务器”JVM根据可用内存使用默认值。当64Mb在2000年成为默认值时(之前的默认值是16Mb),它看起来一定很大,但现代应用程序很容易耗尽它。
这意味着您通常必须使用-Xms和-Xmx命令行参数显式地调整堆的大小:
java -Xms256m -Xmx512m MyClass设置最小和最大堆大小有许多经验法则。显然,最大值必须足够高,以容纳程序所需的所有对象。但是,将其设置为“刚好足够大”不是一个好主意,因为这样会增加垃圾收集器的工作负载。相反,对于长时间运行的应用程序,您应该计划保持20–25%的堆为空(尽管您的特定应用程序可能需要不同的设置;GC调优是一门超出本文范围的技术)。
令人惊讶的是,最小堆大小通常比最大值更重要。垃圾收集器将尝试保持当前堆的大小,而不是增加堆的大小。这可能导致程序创建和丢弃大量对象,但所需内存永远不会超过初始(最小)堆大小。堆将保持在该大小,但垃圾收集器将不断运行以使其保持在该大小。在生产环境中,我认为将最小和最大界限设置为相同的值是有意义的。
您可能想知道我为什么要费心限制最大大小:毕竟,除非实际使用了物理内存,否则操作系统不会分配物理内存。部分原因是虚拟地址空间必须容纳的不仅仅是Java堆。如果您在32位系统上运行,那么较大的最大堆大小可能会限制类路径上jar的数量,或者限制您可以创建的线程的数量。
限制最大堆大小的另一个原因是它可以帮助您发现代码中的任何内存泄漏。开发环境往往不会给应用程序带来压力。如果您在开发过程中使用了一个巨大的最大堆大小,您可能永远不会意识到内存泄漏,直到您进入生产环境。
观察垃圾收集器工作
所有JVM都提供-verbose:gc选项,它告诉垃圾收集器在控制台运行时向控制台写入日志消息:
java -verbose:gc com.kdgregory.example.memory.SimpleAllocator
[GC 1201K->1127K(1984K), 0.0020460 secs]
[Full GC 1127K->103K(1984K), 0.0196060 secs]
[GC 1127K->1127K(1984K), 0.0006680 secs]
[Full GC 1127K->103K(1984K), 0.0180800 secs]
[GC 1127K->1127K(1984K), 0.0001970 secs]
...Oracle JVM提供了两个附加选项,可以按代显示细分情况,以及收集开始的时间:
java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps com.kdgregory.example.memory.SimpleAllocator
0.095: [GC 0.095: [DefNew: 177K->64K(576K), 0.0020030 secs]0.097: [Tenured: 1063K->103K(1408K), 0.0178500 secs] 1201K->103K(1984K), 0.0201140 secs]
0.117: [GC 0.118: [DefNew: 0K->0K(576K), 0.0007670 secs]0.119: [Tenured: 1127K->103K(1408K), 0.0392040 secs] 1127K->103K(1984K), 0.0405130 secs]
0.164: [GC 0.164: [DefNew: 0K->0K(576K), 0.0001990 secs]0.164: [Tenured: 1127K->103K(1408K), 0.0173230 secs] 1127K->103K(1984K), 0.0177670 secs]
0.183: [GC 0.184: [DefNew: 0K->0K(576K), 0.0003400 secs]0.184: [Tenured: 1127K->103K(1408K), 0.0332370 secs] 1127K->103K(1984K), 0.0342840 secs]
...这告诉我们什么?好吧,首先,垃圾收集是经常发生的。每行中的第一个字段是JVM启动后的秒数,我们每几百分之一秒就会看到一次集合。事实上,将集合的开始时间添加到其执行时间(显示在行尾)之后,似乎收集器一直在运行。
在实际的应用程序中,这将是一个问题,因为收集器会占用程序的CPU周期。正如我上面提到的,这可能意味着初始堆大小太小,日志证实了这一点:每当堆达到1.1 Mb时,它就会被收集起来。如果看到这种情况,请在更改应用程序之前增加-Xms值。
这个日志还有一个有趣的地方:除了第一个集合之外,年轻代“DefNew”中没有存储任何对象。这表明程序正在分配大的数组,而其他什么都没有——这是任何真实世界的程序都不应该做的。如果我在实际的应用程序中看到这一点,我的第一个问题是“这些数组是用来做什么的?
heap dump 堆转储
堆转储向您显示应用程序正在使用的对象。在最基本的情况下,它只是按类计算实例数和字节数。您还可以获取显示分配内存的代码的转储,并将历史计数与活动计数进行比较。但是,收集的信息越多,给运行中的JVM增加的开销就越大,因此其中一些技术只适用于开发环境。
如何获得堆转储dump文件
-XX:+HeapDumpOnOutOfMemoryError命令行参数是生成堆转储dump文件的最简单方法。顾名思义,只有当程序内存不足时,它才会生成转储,这使得它适合于生产使用。但是,因为它是一个事后转储,所以它只能提供对象的直方图。此外,它创建了一个二进制文件,您必须使用jhat工具来检查该文件(该工具是jdk1.6发行版的一部分,但将读取jdk1.5 jvms生成的文件)。
jmap命令(从1.5开始提供)允许您从运行的JVM生成堆转储dump文件,jhat的dump文件或简单的文本直方图。直方图是一个很好的第一行分析,特别是当您在一段较长的时间内多次运行它时,或者当您将活动对象计数与历史分配计数进行比较时。
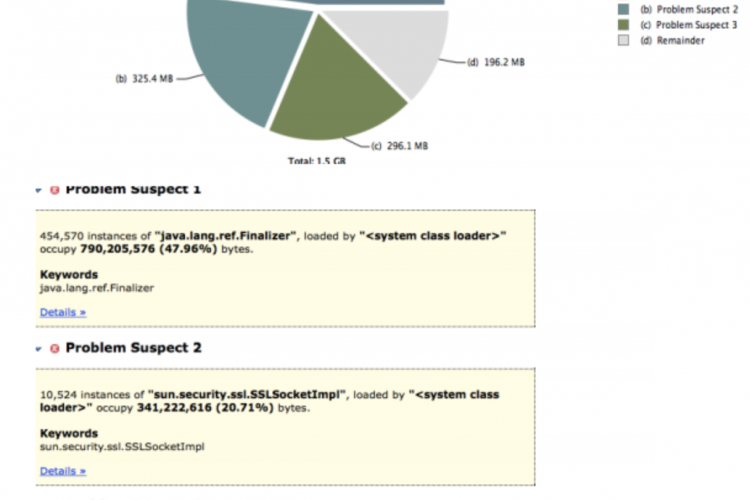
在规模的最末端,无论是在信息方面还是在开销方面,都是探查器。探查器使用JVM的调试接口来收集有关对象分配的详细信息,包括代码行和调用堆栈。这是非常有用的:您可以看到您在一个位置分配了950MB,而不是仅仅知道您已经分配了1GB的阵列,并且可以忽略其他位置。当然,这些信息是有代价的,包括CPU消耗和存储原始数据的内存。不允许您在生产环境中运行探查器。
堆转储分析:活动对象
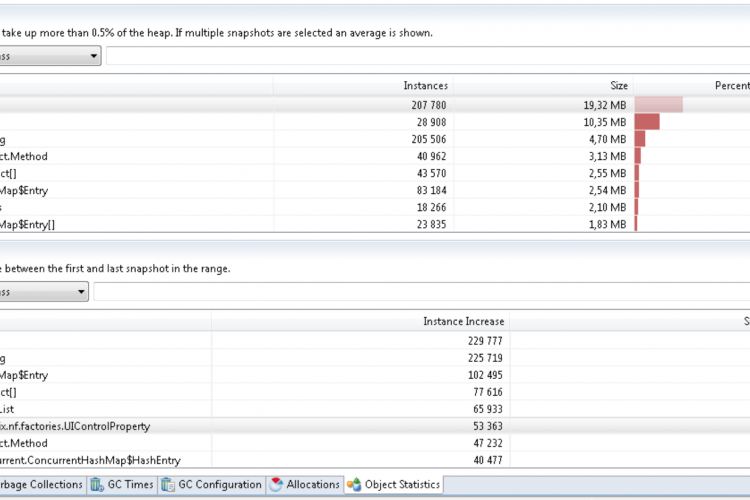
Java内存泄漏的定义是,分配对象而不清除对它们的所有引用,这意味着垃圾收集器无法回收它们。堆直方图是开始查找此类泄漏的一种简单方法:它不仅显示堆中的对象,还显示它们消耗的内存量。简单直方图的主要缺点是,同一类的所有对象都被分组在一起,因此您必须做一些检测工作来找出它们的分配位置。
使用-histo选项调用jmap会得到一个直方图,显示自程序启动以来创建的所有对象(包括已经收集的对象)的计数和内存消耗。使用-histo:live仍然在堆上的对象的计数,无论它们是否符合收集条件。
这意味着,要获得准确的计数,需要在调用jmap之前强制运行垃圾收集器。如果您在本地运行应用程序,最简单的方法是使用jconsole:在“内存”选项卡的顶部,有一个标记为“执行GC”的按钮。如果您在服务器环境中运行,并且暴露了JMX bean,则在java.lang组有一个gc()操作。如果这两个选项都不可用,则可以一直等待正常的垃圾回收。然而,如果您有一个严重的泄漏,那么第一个主要的收集很可能是OutOfMemoryError的直接前兆。
显示所有对象(甚至是已收集的对象)的直方图对于查找“热门”对象也很有用:那些经常被分配和丢弃的对象。如果用O(N2)算法创建临时对象,它将立即从直方图中显现出来。
有两种方法可以使用jmap生成的直方图。最有用的技术,特别是对于长时间运行的服务器应用程序,是在一个较长的时间段内多次调用“live”选项,并调查那些计数不断增加的对象。但是,根据服务器负载的不同,可能需要一个小时或更长时间才能获得好的信息。
一种更快的方法是将活动对象与总对象进行比较。那些带电计数占总数很大一部分的物体可能存在泄漏。下面的示例显示了一个存储库管理器的前十几个条目(近2500个条目中),该存储库管理器已经为100多个用户提供了几个星期的服务。据我所知,这个程序并没有内存泄漏,但是它的正常操作会导致堆转储,这与那些有内存泄漏的程序类似。
~, 510> jmap -histo 7626 | more
num #instances #bytes class name
----------------------------------------------
1: 339186 63440816 [C
2: 84847 18748496 [I
3: 69678 15370640 [Ljava.util.HashMap$Entry;
4: 381901 15276040 java.lang.String
5: 30508 13137904 [B
6: 182713 10231928 java.lang.ThreadLocal$ThreadLocalMap$Entry
7: 63450 8789976 <constMethodKlass>
8: 181133 8694384 java.lang.ref.WeakReference
9: 43675 7651848 [Ljava.lang.Object;
10: 63450 7621520 <methodKlass>
11: 6729 7040104 <constantPoolKlass>
12: 134146 6439008 java.util.HashMap$Entry
~, 511> jmap -histo:live 7626 | more
num #instances #bytes class name
----------------------------------------------
1: 200381 35692400 [C
2: 22804 12168040 [I
3: 15673 10506504 [Ljava.util.HashMap$Entry;
4: 17959 9848496 [B
5: 63208 8766744 <constMethodKlass>
6: 199878 7995120 java.lang.String
7: 63208 7592480 <methodKlass>
8: 6608 6920072 <constantPoolKlass>
9: 93830 5254480 java.lang.ThreadLocal$ThreadLocalMap$Entry
10: 107128 5142144 java.lang.ref.WeakReference
11: 93462 5135952 <symbolKlass>
12: 6608 4880592 <instanceKlassKlass>查找内存泄漏时,请从消耗最多内存的对象开始。这听起来很明显,但有时它们并不是泄漏的源头。不过,这是最好的开始,在这种情况下,char[]实例消耗的内存最多(尽管这里的总内存是60Mb,这不是什么问题)。令人担忧的是,“实时”计数几乎是“分配”计数的三分之二。
一个普通的程序分配对象,然后释放它们;如果它长时间持有对象,那就是一个可能的泄漏。但话说回来,一个特定的程序所经历的“搅动”的数量取决于程序在做什么。字符数组几乎总是与字符串相关联,有些程序只是在程序的生命周期中保留了大量字符串。例如,基于JSP的应用服务器为JSP中的每个HTML块定义字符串。这个特殊的程序确实提供HTML,但是它对字符串的需求并不是那么明确:它提供目录列表,而不是大量的静态文本。如果内存不足,我会尝试找出这些字符串被分配到哪里,以及为什么没有丢弃它们。
另一个值得关注的领域是字节数组(“[B”)。JDK中有很多类使用它们(例如,BufferedInputStream),但在应用程序代码中很少看到它们。通常它们被用作缓冲区,但缓冲区应该是短期的。在这里,我们看到有一半以上的字节数组仍然被认为是活动对象。这是令人担忧的,它突出了一个简单直方图的问题:单个类的所有对象都被分组在一起。对于应用程序对象,这不一定是个问题,因为它们通常分配在程序的一个部分中。但是字节数组是到处分配的,而且大多数分配都隐藏在库中。我们应该搜索调用new byte[]的代码还是调用new ByteArrayOutputStream()的代码?
堆转储输出使用类名的“内部形式”。大多数情况下,名称都是您所期望的,除了JVM内部的数组和类。后者以“<”开头,前者以“[”开头。基本数组在括号后面加一个大写字符(您可以在JavaDoc中找到Class.getName()). 对象数组在这个括号后面有一个大写的“L”、组件类名和一个分号。多维数组用多个括号表示。
堆转储分析:关联因果关系
要找到泄漏的最终原因,按类计算字节数可能不够。相反,您必须将正在泄漏的对象与您的程序正在分配的对象相关联。一种方法是更仔细地查看实例计数,以便将分配在一起的对象关联起来。下面是一个(匿名的)堆转储的摘录,它来自一个内存有问题的程序:
num #instances #bytes class name
----------------------------------------------
1: 1362278 140032936 [Ljava.lang.Object;
2: 12624 135469922 [B
...
5: 352166 45077248 com.example.ItemDetails
...
9: 1360742 21771872 java.util.ArrayList
...
41: 6254 200128 java.net.DatagramPacket如果您只查看这个堆转储的顶行,您可能会开始对分配了Object[]和byte[]的代码进行徒劳的搜索。真正的罪魁祸首是ItemDetails和DatagramPacket:前者分配了多个ArrayList实例,每个ArrayList实例又分配了一个Object[],而后者使用byte[]保存从网络检索到的数据。
第一个问题,分配太大的数组,实际上不是泄漏。默认的ArrayList构造函数分配一个包含10个元素的数组,而程序只使用了一个或两个元素;在64位JVM上,每个实例浪费了62个字节。一个更聪明的类设计将只在需要时使用一个列表,为每个实例节省额外的48字节。然而,这样的改变需要付出努力,增加内存通常更便宜。
datagram泄漏更麻烦(也更难修复):它表明接收到的数据处理速度不够快。
为了追踪这些因果链,您需要知道应用程序如何使用对象。没有多少程序分配一个Object[]:如果它们使用数组,它们通常会使用类型化数组。另一方面,ArrayList在内部使用对象数组。但是知道内存被ArrayList实例占用是不够的。你需要在链的上面移动一步,找到保存这些列表的对象。
一种方法是查找相关的实例计数。在上面的例子中,byte[]与DatagramPacket的关系很明显:一个几乎是另一个的两倍。然而,ArrayList和ItemDetails之间的关系并不是很明显(事实上,每个ItemDetails实例都有几个列表)。
这种情况下的技巧是将注意力集中在具有高实例计数的任何其他类上。我们有一百万个ArrayList实例;它们要么分布在不同的类中,要么集中在少数几个类中。无论如何,一百万个参考资料是很难隐藏的。即使有十几个类拥有一个ArrayList,这些类仍然有100000个实例。
从柱状图中追踪这样的链是一项艰巨的工作。幸运的是,jmap不仅限于直方图,它还将生成可浏览的堆转储。
堆转储分析:遵循引用链
浏览堆转储有两个步骤:首先,使用-dump选项调用jmap,然后对结果文件调用jhat。但是,如果您需要走这条路,请确保有足够的可用内存:转储文件很容易就有数百兆字节,jhat可能需要几千兆字节来处理该文件。
tmp, 517> jmap -dump:live,file=heapdump.06180803 7626
Dumping heap to /home/kgregory/tmp/heapdump.06180803 ...
Heap dump file created
tmp, 518> jhat -J-Xmx8192m heapdump.06180803
Reading from heapdump.06180803...
Dump file created Sat Jun 18 08:04:22 EDT 2011
Snapshot read, resolving...
Resolving 335643 objects...
Chasing references, expect 67 dots...................................................................
Eliminating duplicate references...................................................................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.默认的URL为您提供了系统中加载的所有类的列表,我很少发现这些类有用。相反,我从http://localhost:7000/histo/,这是一个直方图视图,可按实例计数或总字节进行排序(单击右侧的图像可查看完整版本)。
这个柱状图中的每个类名都是一个链接,可以将您带到该类的详细信息页面。在这里,您将看到类在类层次结构中的位置、其成员变量以及对类实例的每个引用的链接。我也不觉得这个页面非常有用,引用列表会增加浏览器的内存使用。
对于跟踪内存问题,最有用的页面是参考摘要。此页有两个表:referers(incoming传入)和referers(outgoing传出),这两个表都是按引用计数预先排序的。单击一个类名将带您进入该类的引用摘要。使用上一节中的ArrayList示例,只需单击六次,就可以从[Ljava.lang.Object对象至com.example.ItemDetails项目详细信息.
您可以从“类详细信息”页访问“引用摘要”页。但我发现直接构建链接更容易:从直方图页面获取类链接(例如:http://localhost:7000/class/0xa5408348),并将“class”替换为“refsByType”(例如:http://localhost:7000/refsByType/0xa5408228)。

堆转储分析:分配站点
大多数时候,知道哪些对象正在消耗内存就足以找出它们被泄露的原因。您可以使用jhat查找对这些对象的所有引用,很可能您会看到保存对象太长的代码。但有时这还不够。
例如,如果您的代码正在泄漏字符串,那么您可能需要几天的时间来遍历所有字符串操作代码。要解决这样的问题,您需要一个堆转储来实际显示分配内存的位置。但是,请注意,这种类型的分析为应用程序增加了极大的开销,因为分析代理必须记录对新操作符的每次调用。
大多数交互式概要文件都可以生成这种级别的数据,但我发现最简单的方法是使用内置的hprof代理启动JVM:
java -Xrunhprof:heap=sites,depth=2 com.kdgregory.example.memory.Gobblerhprof有很多选择:它不仅可以以各种方式分析内存使用情况,还可以跟踪CPU消耗。您将在下面找到一个Sun技术文章的链接,该文章描述了这些选项。对于这次运行,我指定了一个已分配对象及其分配位置的事后转储,分辨率为两个堆栈帧。输出将写入文件java.hprof.txt文件,堆转储部分如下所示:
SITES BEGIN (ordered by live bytes) Tue Sep 29 10:43:34 2009
percent live alloc'ed stack class
rank self accum bytes objs bytes objs trace name
1 99.77% 99.77% 66497808 2059 66497808 2059 300157 byte[]
2 0.01% 99.78% 9192 1 27512 13 300158 java.lang.Object[]
3 0.01% 99.80% 8520 1 8520 1 300085 byte[]
SITES END这个特殊的程序不会分配很多不同的对象类型,也不会在许多不同的地方分配它们。一个普通的转储有数百或数千行长,显示分配了特定对象类型的每个站点。幸运的是,大多数问题出现在转储的前几行。在本例中,跳出的是64MB的活动字节数组,特别是因为它们平均每个约32k。
大多数程序不需要保存那么多数据,因此这表明程序没有正确地提取和汇总它处理的数据。在读取大字符串然后保留子字符串的程序中,您经常会看到这种情况:这是一个鲜为人知的实现细节String.substring() 表示它与原始字符串共享一个字符数组。如果您逐行读取一个文件,但只使用每行的前五个字符,则仍将整个文件保存在内存中。
此转储还显示这些数组的分配计数等于活动对象的计数。这是一个典型的泄漏,我们可以通过搜索“跟踪”号找到实际代码:
TRACE 300157:
com.kdgregory.example.memory.Gobbler.main(Gobbler.java:22)好吧,这很简单:当我转到代码中的那一行时,我看到我将数组存储在一个永远不会超出范围的ArrayList中。但是,有时堆栈跟踪与您编写的代码没有连接:
TRACE 300085:
java.util.zip.InflaterInputStream.<init>(InflaterInputStream.java:71)
java.util.zip.ZipFile$2.<init>(ZipFile.java:348)在这种情况下,需要增加堆栈跟踪的深度并重新运行应用程序。这里有一个折衷方法:当捕获更多堆栈帧时,会增加分析的开销。如果未指定深度值,则默认值为4。我发现我的代码中的大多数问题都可以在深度为2的情况下被发现,尽管我运行的深度高达12(在一台物理内存为5千兆字节的机器上;这是一个颠簸,分析运行花了将近一个小时,但我发现了问题)。
增加堆栈深度的另一个好处是,报告将更加精细:您可能会发现您从两个或三个地方泄漏对象,所有这些地方都使用公共方法。
堆转储分析:位置
分代垃圾收集器之所以能工作,是因为大多数对象在分配后不久就会被丢弃。您可以使用相同的原则来查找内存泄漏:使用调试器,在分配站点设置断点,然后遍历代码。在几乎所有情况下,您都会看到它在分配后不久添加到一个长寿命的集合中。
除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1309.html

 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论