 我正在研究我继承的一些Java代码。我正在关键的地方做一些速度改进,为了测试我的改进,我需要测试用例来比较不同的实现。不幸的是,手动生成测试用例太耗时了(需要数千个,手动生成一个测试用例需要几分钟甚至几个小时)。不幸的是,随机生成的测试用例也不起作用,因为我的测试用例是(命题的)LTL公式,并且随机生成的一个我期望在实际使用程序时出现的大小,是不太可能令人满意的,而现实生活中的公式是期望的,这在一定程度上得益于程序的持续集成和测试工具。
我正在研究我继承的一些Java代码。我正在关键的地方做一些速度改进,为了测试我的改进,我需要测试用例来比较不同的实现。不幸的是,手动生成测试用例太耗时了(需要数千个,手动生成一个测试用例需要几分钟甚至几个小时)。不幸的是,随机生成的测试用例也不起作用,因为我的测试用例是(命题的)LTL公式,并且随机生成的一个我期望在实际使用程序时出现的大小,是不太可能令人满意的,而现实生活中的公式是期望的,这在一定程度上得益于程序的持续集成和测试工具。
为了解决这个问题,我设计了一个简单的计划:生成测试用例并根据它们是否可满足对它们进行排序,并为不易分类的公式添加第三个类别(即,在使用简单但快速高效的实现进行测试时内存不足)。这一切导致我产生了数十万个公式,测试它们是否令人满意,收集其中一些,然后丢弃其余的。
这应该很简单,但我注意到我的程序在运行时的奇怪行为:执行之后,它变慢了,容易分类的公式变得更加频繁。在一个例子中,我没有可满足的公式,8000个不可满足的公式和1或2个失败。让计算运行,我有0个可满足的公式,9000个不可满足的公式,还有20个失败。然后程序内存不足。这种行为是不可能的:我在生成过程中捕捉到OutOfMemoryException,然后应该释放所有内存,所以我永远不会耗尽内存。其次,公式是完全随机生成的,因此8000次运行中有2次失败,但1000次运行中有18次失败似乎不太可能。总而言之,这指向了内存中积累的东西。
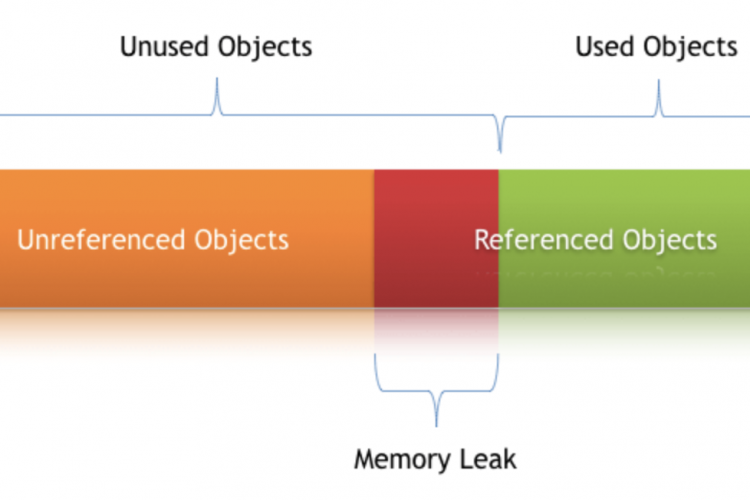
通常,您可以查看代码和发生内存泄漏的pin点。在垃圾收集语言(如Java)中,通常会以两种方式遇到内存泄漏:垃圾收集器看不到某些内存不再使用,或者您忘记删除对不再使用的对象的引用。前者不太可能,因为Java使用非常复杂的技术,包括遍历整个堆的标记和扫描算法(尽管这不是非常频繁地运行,因为它的计算成本很高)。这两者中的哪一个是真正的问题并不重要,因为解决方法是相同的:确保将不再使用的引用设置为null,这样垃圾收集器就可以发现它们不再使用。
您可能有兴趣看看java.lang.ref package。它包含的类可以让您与垃圾收集器交互,特别是WeakReference,它引用一个对象,但不会强制它停留在内存中,因此,如果只有对对象的弱引用,则可以对它进行垃圾收集,而SoftReference,它引用的对象应该保存在内存中,但如果程序内存不足,则可以对其进行垃圾回收。弱引用对于实现工厂非常有用,这些工厂确保a.equals(b)那么a==b。如果对复杂对象进行大量比较,这是一个优势,可以通过向工厂添加一组生成的对象并确保始终在该集中查找对象并在要求时返回相同的实例来实现创造一个相等的。不幸的是,除非使用弱引用,否则您的集合将使对象保持活动状态,从而导致内存泄漏。软引用对于创建复杂计算的内存缓存或从较慢的存储中获得的值非常有用。可以很容易地重新计算/重新读取该值,但不这样做会更快。因此,如果可能,缓存的值应该保存在内存中,但是如果应用程序需要内存用于其他用途,则回收缓存比将重要值交换到磁盘更有用。
使用JConsole监视程序
首先要做的是弄清楚程序是否真的在泄漏内存。我们可以使用JConsole来实现这一点,JConsole附带JDK表单Sun(或Oracle,但我不喜欢它们,因为它们将java api放在一个速度较慢的服务器上)。我们只需启动JConsole(在osx或Unix上,只要在提示符处键入JConsole,在Windows上,我想可以在开始菜单中找到JConsole)。首先,我们选择要监控的流程:

当JConsole启动时,我们切换到Memory选项卡并监视内存。由于我们对长时间行为感兴趣,我们选择只显示堆对象的最老年代。年轻代的波动很大,我像疯了一样分配和销毁物品,我们只关心是否有东西积累起来,这意味着它最终会被提升到旧的状态。为了更好地衡量,我们可以偶尔点击performgc按钮来清理内存。这会使使用的内存略有减少,但您仍会得到这样的总体趋势:

这是一个不健康程序的内存配置文件:大小只会增加。3或4个颠簸是因为我按了执行GC按钮。当内存消耗达到2GB时,它会变平(因为我已经强迫Java最多使用2GB内存)。当内存达到2GB时,性能也会明显下降,我的程序现在每隔一段时间就会停止执行垃圾回收。这肯定很糟糕。
生成堆映像
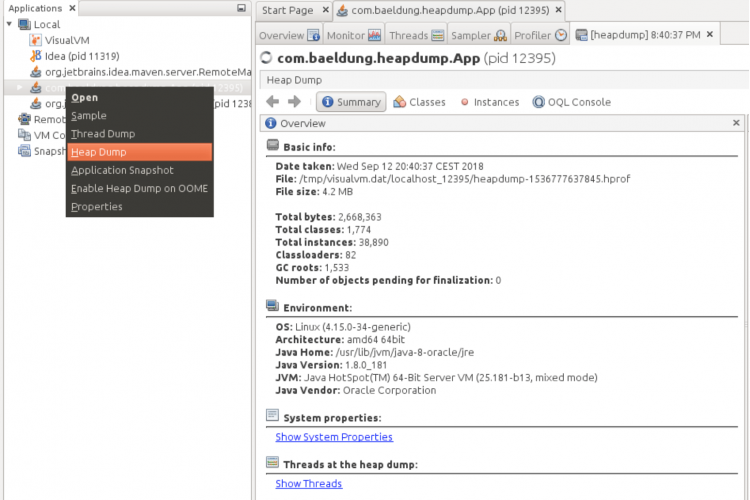
现在,我们已经确定我的代码包含内存泄漏。我们如何从那里继续?一种方法是遍历我们的代码并随机删除引用,直到您不再看到错误的行为,但这有点特别,而且很难知道何时完成。相反,我们将使用内存分析器。幸运的是,JDK内置了所有需要的工具。您所要做的就是创建一个堆映像,并对孤立对象进行分析。
基本上可以用两种方法生成堆,每种方法各有优缺点:使用hprof或使用jmap。使用hprof要慢得多,但可以提供更多信息,例如类名和分配堆栈,而jmap全速运行程序,但只提供某些类的名称。这一部分是基于这篇博客文章,但我的文章使选项和阶段之间的区别更清楚,并提供了图片。
使用hprof
只需使用hprof启动您的程序:
java -Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=9000 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
-agentlib:hprof=heap=dump,file=hprof.bin,format=b,depth=10 \
-jar java_app.jar这基本上启动探查器,禁用所有安全性并告诉它转储到一个名为hprof.bin文件. 如果您的程序不在jar文件中,您可以简单地用应用程序的主类替换最后一行。现在练习您的程序,完成后,按Ctrl-C转储堆并退出应用程序。
使用jmap
正常启动程序,可以从命令行、文件管理器(Finder或Windows资源管理器或现在Lunix用户使用的任何讨厌的工具)或IDE启动程序。然后找到程序的进程id。您可以用几种不同的方法来实现这一点,但更简单的方法是查看JConsole,在JConsole中可以使用它。在上面的示例中,进程id是59735(请参阅进程选择屏幕上的PID列或监视进程时的标题栏)。现在练习你的程序。
然后使用jmap转储图像:
jmap -dump:format=b,file=hprof.bin 59735记住用JConsole找到的进程id替换59735。
训练你的程序
我们现在从两个不同的分支合并。你的读者没有比你更愉快的阅读体验,但是你呢?嗯,我们需要锻炼我们的计划。也就是说,执行我们认为会导致错误的操作。在我的例子中,我应该启动程序并让它运行,但是你可能需要加载一个文件,打印它或者你的程序做什么。重复几次,这样堆中的错误就更明显了。
分析堆映像
当我们使用任何一种方法生成了一个堆映像时,就应该分析它了。幸运的是,JDK有这样一个工具,jhat(我不知道是谁想出了这些名字,但他们应该被枪杀)。以以下方式开始jhat:
jhat -J-Xmx2G hprof.bin注意-J和-Xmx2G之间没有空格,我们设置这个选项是为了允许jhat使用2GB的RAM,这可能需要它来分析我们相当大的堆映像。
jhat将处理(这可能需要很长时间),并在本地计算机上的端口7000上启动一个web服务器,因为为什么不呢。要查看生成的数据,请将浏览器指向localhost:7000。你会得到这样的结果:

立即滚动到底部:

选择Show heap histogram链接(注意:你的浏览器可能没有一个红色的矩形指出正确的链接,正如我在后处理中添加的那样)。对于我的应用程序,如果使用hprof,柱状图如下所示:

或者像这样如果我用jhat的话:

数字不同,因为hprof的时间取决于我愿意等待多长时间,而jmap的时间取决于我转储图像的速度。注意,jmap输出并不总是显示好的类名。在下面,我将只显示hprof输出,因为它更好,但是使用jmap输出也可以完成任何事情。
这个输出应该像一个普通的profiler输出一样阅读:关注那些你拥有很多的输出。在我的例子中,我有一大堆公式和HashMap$Entry类。事实上,我比其他任何东西都多了几百个。这是有道理的,我有一堆公式类,因为我处理公式,但不超过一百万。虽然数据结构是递归的,但对于一个复杂的公式,我可能会用几千,而不是一百万。另外,HashMap$条目也吸引了我。这表示某个东西存储在HashMap中,并且比较这些数字,表明某些东西可能只是公式。查看Formula类没有显示HashMap,所以我有点不知所措:什么包含所有这些公式?
为了调查,让我们看看所有这些公式。我们点击公式得到这个屏幕:

快速地按类型链接引用摘要,因为它开始加载一个很长的列表,其中包含超过一百万个引用,这可能会杀死你的浏览器。然后我们看到:

这告诉我们两件事:Formula显然是递归数据类型(大多数实例由其他Formula对象引用),其余的由HashMap$Entry对象引用。第三个地方的公式数组是可以的,因为它包含生成公式的模板(我可以通过链接看到这一点,但我没有在这里显示)。让我们轻点HashMap$条目,看看它会带我们去哪里。它把我们带到这里:
因此,它们要么从数组引用,要么从其他HashMap$Entry对象引用。Guess Java的哈希表是通过使用HashMap$Entry对象的链表来处理冲突的条目数组来实现的。18000次碰撞并不是很好…总之,让我们看看数组:
毫不奇怪,这些都在HashMaps中。以下内容:
这些代码在很多地方都有使用,但是我的代码只在少数地方出现。节点非常有意义:我确实有一些引用节点的图,节点的数量似乎很小,可以理解。SinglePropertyGraph还包含公式,而且对象的数量(1)再次非常合理。不过,DefaultFormulaFactory有点奇怪。为什么它要有一个公式图?而且,它是唯一一个在我的代码执行过程中存在的对象。启动Eclipse并加载工厂:
好像我们找到了罪魁祸首。工厂规范化公式对象。这显然是不好的,当你产生数以百万计。规范化对象的原因是为了允许快速比较,所以我可以使用WeakReferences来解决这个问题,但是我使Formula对象不可变(无法修改),并添加了哈希值的预计算和有效的相等函数:
现在,我刚刚摆脱了规范化,取而代之的是更有效的哈希函数和等式测试。然后我运行我的回归测试,以确保我没有破坏任何东西(回归测试创建起来很糟糕,但当你做这样的事情时,它们真的很震撼)。
验证内存泄漏是否消失
为了验证这是否真的修复了内存泄漏,我再次尝试JConsole,它现在显示了如下内容:
即使随着时间的推移,我们的内存消耗也不再稳定增长。钉子没问题。
为了确保我没有错过任何东西,我再开始我的程序。我让运行几秒钟并创建一个转储(使用jmap),让程序继续运行一两分钟并创建一个辅助转储(到一个新文件)。
然后我们又去查jhat,这次
jhat -J-Xmx2G -baseline heap1.bin heap2.bin这里heap1.bin是我修复错误后生成的第一个堆映像,heap2.bin是我让程序运行几分钟后创建的映像。-baseline选项告诉jhat使用第一个堆映像作为基线,并将两个映像中的任何对象标记为“old”,将仅在后一个映像中的任何对象标记为“new”。启动浏览器,我们现在选择显示实例计数链接整洁的底部:
这显示了有多少实例以及其中有多少是新实例:
这表明,虽然我仍然有很多公式实例,但所有这些都是新的,因此我没有泄漏任何公式实例。任何与HashMap相关的问题也是如此。事实上,我看到几乎所有的对象都是新的,这是不寻常的,但对我的程序来说是非常有意义的,它分配一堆公式,测试它们,转储它们,然后丢弃它们。
结论
在这里,我们看到了如何使用JDK提供的工具来消除程序中的内存泄漏。我的程序有点特别,因为随着时间的推移,它几乎会转储内存中的所有内容,使得检测内存泄漏特别容易。不过,用于验证内存泄漏是否已被发现和删除的技术也可以用于一般情况:例如,启动程序并使其处于稳定状态。然后倒垃圾。现在练习你的程序,使它回到稳定状态。然后创建一个新的转储,并将其与旧转储进行比较。您应该几乎看不到任何新对象-新对象对应于泄漏。
您还可以探索程序的一些选项;例如,jmap有一个-histo选项,它可以立即在控制台中显示内存历史记录,这比生成和分析转储文件要快得多。
除此之外,它只是关于在时间和空间上对代码进行分析,并确保在出于性能原因对工作程序进行更改之前拥有可靠的回归测试套件。

除特别注明外,本站所有文章均为老K的Java博客原创,转载请注明出处来自https://javakk.com/1140.html


 在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it
在这个努力程度如此低下的时代,还轮不到比拼天赋。静下心来,just do it

暂无评论